- Best-IA Newsletter
- Posts
- Boletín Semanal Best-IA #103
Tutoriales
4 casos de uso modo del Agente de ChatGPT
Colección de plantillas y prompts para Claude Code
Incluye agentes de código, bases de datos, seguridad, documentación y más:
Noticias
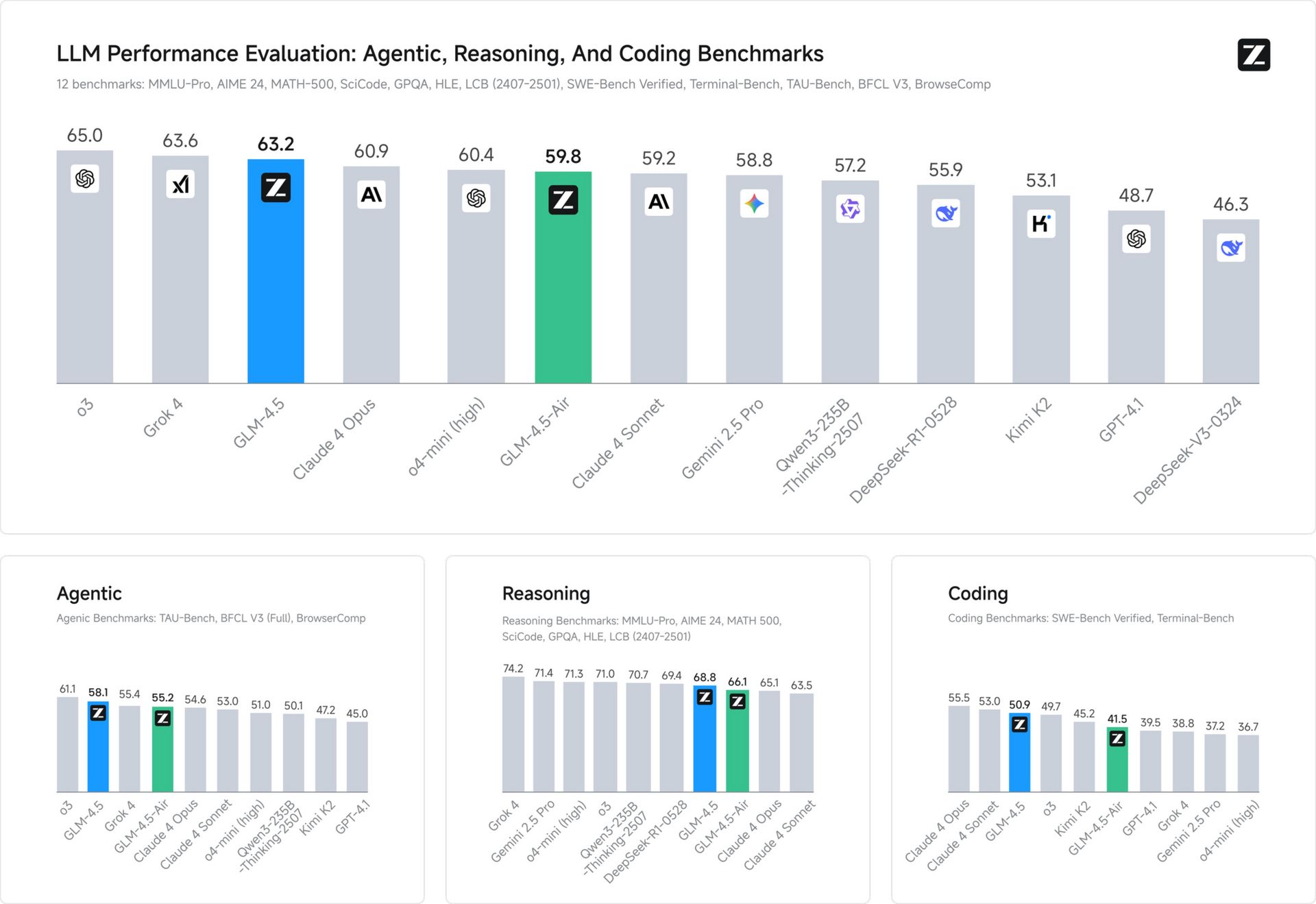
GLM-4.5: Z.ai lanza su asalto al trono con licencia MIT
Z.ai AI ha presentado GLM-4.5 y su versión ligera GLM-4.5-Air, dos modelos open source que compiten con Claude 4 Opus y superan a Gemini 2.5 Pro en tareas de razonamiento, codificación y agentes, todo bajo una licencia MIT.
🔑 Puntos clave del modelo
Dos modos, una mente: GLM-4.5 alterna entre “thinking mode” para razonamientos complejos y “non-thinking mode” para respuestas rápidas, ajustando coste y latencia según el reto.
MoE optimizado: Con arquitectura Mixture of Experts, usa solo 32B (GLM-4.5) o 12B (Air) de sus parámetros totales, logrando eficiencia sin pérdida de calidad gracias a sigmoid gates y balance routing.
Rendimiento top en benchmarks:
🧠 AIME24: 91.0 (vs Claude 4 Opus 75.7)
🧮 MATH500: 98.2 (vs GPT-4.1 96.7)
🧪 GPQA: 79.1 (ligeramente por debajo de Gemini 2.5 Pro)
🛠 SWE-bench Verified: 64.2
🖥 Terminal-Bench: 37.5
Diseño técnico puntero:
Arquitectura profunda y estrecha (más capas, menos expertos).
128K tokens de contexto, función calling nativa, y atención con 96 cabezas vía GQA y RoPE parcial.
Entrenamiento masivo: 22T tokens, incluyendo 7T específicos de código y razonamiento.
🎯 ¿Por qué importa?
GLM-4.5 no solo brilla en rendimiento, sino que su combinación de potencia, eficiencia y apertura (MIT) lo convierten en una alternativa real para empresas, desarrolladores y comunidad científica que buscan modelos punteros sin depender de soluciones cerradas.
Pruébalo en https://chat.z.ai/
Intern-S1: el nuevo modelo open source que entiende ciencia como un experto
InternLM ha lanzado Intern-S1, un modelo multimodal de código abierto que no solo compite con modelos comerciales cerrados, sino que establece nuevos estándares en tareas científicas. Con una arquitectura Mixture of Experts (MoE) de 235B y un encoder visual de 6B, está diseñado para razonar con textos, fórmulas químicas, proteínas o señales sísmicas.
🔑 Puntos clave de Intern-S1
Arquitectura híbrida potente: combina un modelo de lenguaje MoE de 235B parámetros con un encoder visual de 6B para razonamiento multimodal avanzado.
Preentrenamiento centrado en ciencia: entrenado con 5 billones de tokens, más del 50% de contenido científico (papers, secuencias, datos especializados).
Tokenizador dinámico: puede interpretar de forma nativa fórmulas moleculares, secuencias de proteínas y señales sísmicas, sin trucos ni transformaciones previas.
Capacidades generales sólidas: además de ciencia, también destaca en tareas de lenguaje general y razonamiento, a la altura de los grandes modelos comerciales.
Código y demo abiertos: disponible en Hugging Face, GitHub y demo web.
🎯 ¿Por qué importa?
Intern-S1 demuestra que el open source no solo puede seguirle el ritmo a los gigantes comerciales, sino que puede superarlos en nichos clave como el razonamiento científico. Es una herramienta estratégica para investigadores, bioinformáticos y desarrolladores que necesitan modelos potentes, transparentes y personalizables.

Deep Think: el modo de razonamiento extendido llega a la app Gemini
Google lanza oficialmente Deep Think, una nueva función dentro de la app Gemini, disponible desde hoy para los suscriptores de Google AI Ultra. Esta versión optimizada del modelo que ganó una medalla de oro en la Olimpiada Internacional de Matemáticas (IMO) busca llevar el razonamiento profundo al día a día de usuarios avanzados y matemáticos.
🔑 Puntos clave
Razonamiento en paralelo y más “tiempo de pensamiento”
Deep Think permite a Gemini explorar múltiples ideas a la vez, combinarlas, refinarlas y elegir la mejor. Esto se traduce en respuestas más creativas y estructuradas para tareas complejas, desde diseño web hasta matemáticas avanzadas.Capacidades de alto nivel en benchmarks exigentes
El modelo alcanza el rendimiento más alto en benchmarks como LiveCodeBench V6 (código) y Humanity’s Last Exam (conocimientos científicos y razonamiento), superando a Gemini 2.5 Pro, OpenAI 03 y Grok 4.Aplicaciones en ciencia, desarrollo y descubrimiento
Deep Think es especialmente útil en procesos iterativos como el desarrollo algorítmico, el diseño escalonado y la formulación de conjeturas matemáticas, potenciando el trabajo de investigadores y desarrolladores.Acceso limitado pero expandiéndose
Los suscriptores de Google AI Ultra ya pueden usarlo en la app Gemini activando la opción desde el menú del modelo. También se está liberando el acceso vía API a un grupo selecto de testers académicos y desarrolladores.Seguridad y responsabilidad mejoradas
Aunque se han incrementado las salvaguardas, el modelo aún tiende a rechazar algunas peticiones benignas. Google continúa aplicando evaluaciones de seguridad avanzadas para asegurar un desarrollo responsable.
🎯 Implicaciones
Deep Think representa un paso firme hacia modelos con mayor autonomía y razonamiento estratégico. Su despliegue marca un punto clave en la carrera por crear IAs que no solo respondan rápido, sino que también piensen con profundidad.
MLE-STAR: el nuevo agente de Google que mejora cómo desarrollamos modelos de IA
Google Research presenta MLE-STAR, un agente de ingeniería de machine learning diseñado para acelerar el desarrollo de modelos. Integra búsqueda web inteligente y refinamiento dirigido de bloques de código, ayudando a los investigadores a resolver problemas, optimizar implementaciones y fomentar la innovación.
Una herramienta que combina automatización y precisión para facilitar el trabajo diario en ciencia de datos e IA.
SensorLM: En modelo fundacional de Google para datos de wearables
Google Research presenta SensorLM, una familia de modelos fundacionales entrenados en 60 millones de horas de datos sensoriales. Diseñado para comprender información de dispositivos wearables, permite consultar y analizar datos corporales mediante lenguaje natural.
Una puerta abierta a nuevas aplicaciones en salud, deporte y seguimiento personalizado, donde los sensores… finalmente pueden hablar por sí mismos.
AlphaEarth y Veo 3: Google acelera el mapeo del planeta y la creación de vídeo con IA
Google DeepMind presenta AlphaEarth Foundations, un modelo capaz de mapear la Tierra con un nivel de detalle sin precedentes. Permitirá a científicos monitorizar la deforestación, evaluar la salud de cultivos y más de forma rápida y precisa, gracias a nuevos conjuntos de datos generados por IA.
Al mismo tiempo, Google lanza Veo 3 y Veo 3 Fast en la API de Gemini, con funciones de imagen a vídeo y texto a vídeo, sonido incluido. Ofrecen mayor control creativo, velocidad mejorada y prompts más precisos para generar contenido audiovisual de alta calidad en cuestión de segundos.
OpenAI lanza "Modo Estudio": aprende con ChatGPT
OpenAI presenta Study Mode en ChatGPT, una nueva función diseñada para ayudar a los estudiantes a entender a fondo los problemas, no sólo resolverlos. Utiliza preguntas socráticas e indicaciones escalonadas para guiar paso a paso, promoviendo un aprendizaje activo y reflexivo.
Ya disponible para usuarios Free, Plus, Pro y Team. Llegará pronto también a ChatGPT Edu.
Microsoft lanza Copilot Mode en Edge: el navegador que colabora contigo
Microsoft presenta Copilot Mode, un nuevo modo experimental en Microsoft Edge que transforma la forma de navegar por la web. En lugar de limitarse a mostrar pestañas, Copilot actúa como un asistente proactivo, capaz de entender lo que buscas, ayudarte a comparar opciones, ejecutar tareas, y mantenerte enfocado.
🔑 Funciones destacadas
Panel unificado de chat, búsqueda y navegación.
Comprensión del contexto de múltiples pestañas para tomar decisiones más rápido.
Navegación por voz y acciones automatizadas (abrir pestañas, comparar productos, ubicar contenido).
Asistencia en segundo plano dentro de cualquier página, sin perder tu lugar.
Privacidad y control total: el usuario decide cuándo y cómo activar Copilot.
Disponible de forma gratuita y opcional en Edge para Windows y Mac, en todos los mercados donde Copilot está presente.
🧠 Command A Vision: Inteligencia Multimodal Empresarial de Alto Nivel
Cohere presentó Command A Vision, su nuevo modelo generativo de IA especializado en comprender imágenes y documentos visuales dentro del entorno empresarial. Diseñado para interpretar desde gráficas financieras hasta formularios escaneados, este modelo combina capacidades visuales de última generación con un enfoque claro en eficiencia y despliegue seguro.
🔑 Puntos clave
Dominio visual con enfoque empresarial
Command A Vision supera a modelos como GPT-4.1 y LLaMA 4 Maverick en benchmarks visuales. Está diseñado para comprender documentos, diagramas y escenas reales, aplicando conocimientos específicos por sector (finanzas, salud, energía...).Automatización documental avanzada
El modelo extrae texto y estructura de documentos escaneados, facturas y formularios. Su modo JSON estructurado permite integrarlo fácilmente a flujos de trabajo empresariales, mejorando la precisión y reduciendo tareas manuales.Comprensión de escenas reales
Va más allá de identificar objetos: detecta relaciones espaciales, contexto e incluso matices en fotos. Ideal para sectores como la construcción, la industria o el retail donde la visión contextual es clave para detectar riesgos o patrones.Despliegue privado y eficiente
Puede funcionar en servidores propios con solo 2 GPUs (A100) o una H100 con cuantización. Esto lo hace apto para empresas reguladas que requieren entornos cerrados y seguros, sin sacrificar rendimiento.Integración con capacidades de texto de Command A
Ofrece RAG con citas, soporte multilingüe y análisis contextual combinado de texto e imagen, todo optimizado para las necesidades empresariales más exigentes.
🎯 Relevancia e implicaciones
Command A Vision marca un avance en la adopción empresarial de la IA multimodal, al ofrecer comprensión visual de alto nivel sin requerir grandes recursos. Esto abre la puerta a automatizar procesos clave con seguridad y eficiencia.
🎬 Wan2.2: Video Generativo con Control Cinematográfico y Código Abierto
Alibaba presentó Wan2.2, el primer modelo generativo de video con arquitectura Mixture of Experts (MoE) completamente open source. Con control detallado sobre estética, cámara y movimiento, Wan2.2 promete revolucionar la creación de contenido audiovisual mediante IA.
🔑 Puntos clave
Primera arquitectura MoE para generación de video
Wan2.2 aplica un sistema de expertos especializados que cooperan durante el proceso de denoising, permitiendo escalar capacidad sin aumentar el coste computacional. Es una novedad absoluta en modelos de video generativo.Control cinematográfico avanzado
El modelo permite modificar directamente parámetros como la iluminación, el color, el movimiento de cámara o la composición de escena, dando a los creadores control estético total sobre el resultado final.Tres modos de uso, todos open source
Wan2.2 ofrece tres versiones:Text-to-Video (T2V)
Image-to-Video (I2V)
Text+Image to Video (TI2V)
Todos con licencias abiertas y modelos disponibles para descarga y uso libre.
Dominio del movimiento complejo
El sistema sobresale en generar videos con movimientos elaborados y fluidos, mejorando uno de los puntos débiles típicos en modelos previos de video IA.
Ideogram lanza Character: coherencia visual con una sola imagen
Ideogram presenta Character, un nuevo modelo de IA capaz de generar imágenes consistentes de un personaje usando solo una imagen de referencia. Mantiene estilo, expresión, escena e iluminación en cada variación.
Ya disponible de forma gratuita para todos los usuarios en web e iOS.
Introducing Ideogram Character -- the first character consistency model that works with just one reference image. Now available to all users for free!
Create consistent character images in any style, expression, scene, and lighting. Who wants video next? 🥺
— Ideogram (@ideogram_ai)
6:00 PM • Jul 29, 2025
Robots
Lume: la lámpara robótica que dobla tu ropa
Syncere AI presenta Lume, una lámpara robótica doméstica diseñada para integrarse de forma natural en el hogar. Su primera función: ayudar con tareas del hogar, empezando por doblar la ropa.
Ya está disponible en preventa, con los primeros envíos programados para verano de 2026.
Introducing Lume, the robotic lamp.
The first robot designed to fit naturally into your home and help with chores, starting with laundry folding.
If you’re looking for help and want to avoid the privacy and safety concerns of humanoids in your home, pre-order now.
— Aaron Tan (@aaronistan)
4:00 PM • Jul 28, 2025
Reflexiones Finales
¿ChatGPT daña el cerebro? OpenAI lo debate en su nuevo podcast
En el episodio 4 del podcast de OpenAI, la jefa de educación Leah Belsky y dos estudiantes universitarios se unen a Andrew Mayne para debatir si usar ChatGPT afecta negativamente al aprendizaje, o si, por el contrario, puede potenciar la educación.
Una charla clave sobre el papel de la IA en el aula, el pensamiento crítico y el futuro del estudio.
Does ChatGPT really cause brain rot?
Our Head of Education Leah Belsky and two college students join @AndrewMayne to discuss this and more on episode 4 of the OpenAI Podcast.
— OpenAI (@OpenAI)
3:02 PM • Jul 30, 2025