- Best-IA Newsletter
- Posts
- Boletín Semanal Best-IA #107
Tutoriales
Tutorial ChatGPT Agent
Nano banana AI para arquitectura y 3D: guía completa para principiantes
MiniMax Voice Design: Tutorial para crear voces con AI
Noticias
OpenAI
Novedades de OpenAI
OpenAI acaba de anunciar una batería de actualizaciones que amplían el alcance de ChatGPT. Aquí te dejamos lo más destacado:
🔑 Lo más relevante
Branch in new chat: ahora puedes bifurcar conversaciones y explorar distintas direcciones sin perder el hilo original.
QuizGPT: nuevo modo de estudio con tests interactivos.
OpenAI Jobs Platform: un portal para conectar talento con empresas que demandan habilidades en IA, acompañado de la certificación OpenAI-Certified.
Controles parentales: los padres podrán vincular cuentas con las de sus hijos, establecer límites y recibir alertas en situaciones sensibles.
Bienestar y salud: conversaciones sensibles serán derivadas a modelos de razonamiento como GPT-5-thinking, con apoyo de un Consejo de Expertos en Bienestar y una red de médicos global.
ChatGPT Projects gratis: disponible en la versión Free con hasta 5 archivos por proyecto, ampliado en planes de pago.
OpenAI for Greece: alianza con el Gobierno griego, la Fundación Onassis y Endeavor Greece para lanzar ChatGPT Edu y un programa acelerador de startups.
¿Por qué los modelos de IA alucinan?
Un nuevo paper de OpenAI explica que las “alucinaciones” de los LLMs no son errores misteriosos, sino una consecuencia natural de cómo se entrenan y evalúan estos sistemas.
🔑 Claves del análisis
El origen está en el pretraining
Aunque los datos fuesen perfectos, los modelos están entrenados para dar siempre una respuesta. Eso genera una presión estadística a equivocarse en vez de admitir “no sé”.Los hechos raros son inevitables
Cumpleaños, eventos únicos o datos poco frecuentes aparecen tan pocas veces en el corpus que el modelo acaba adivinando. En estos “one-shot facts”, las alucinaciones son prácticamente inevitables.La capacidad del modelo marca un límite
Modelos débiles —como los basados en n-gramas— no logran distinguir contextos complejos, lo que fija un mínimo de error estructural que no se elimina ni con buen entrenamiento.El post-training refuerza el problema
Los benchmarks actuales premian adivinar con confianza y castigan la abstención. Resultado: los modelos aprenden a sonar seguros incluso cuando no lo están.La propuesta: recompensar la honestidad
Si los sistemas de evaluación valoran abstenerse cuando no hay confianza, los modelos tenderán a calibrar mejor su comportamiento, priorizando precisión y fiabilidad frente a “bluffing”.
🎯 Relevancia
Este cambio de enfoque apunta a una IA más confiable: modelos que saben cuándo responder y cuándo callar, reduciendo alucinaciones y alineando su uso con aplicaciones críticas en ciencia, educación y negocios.
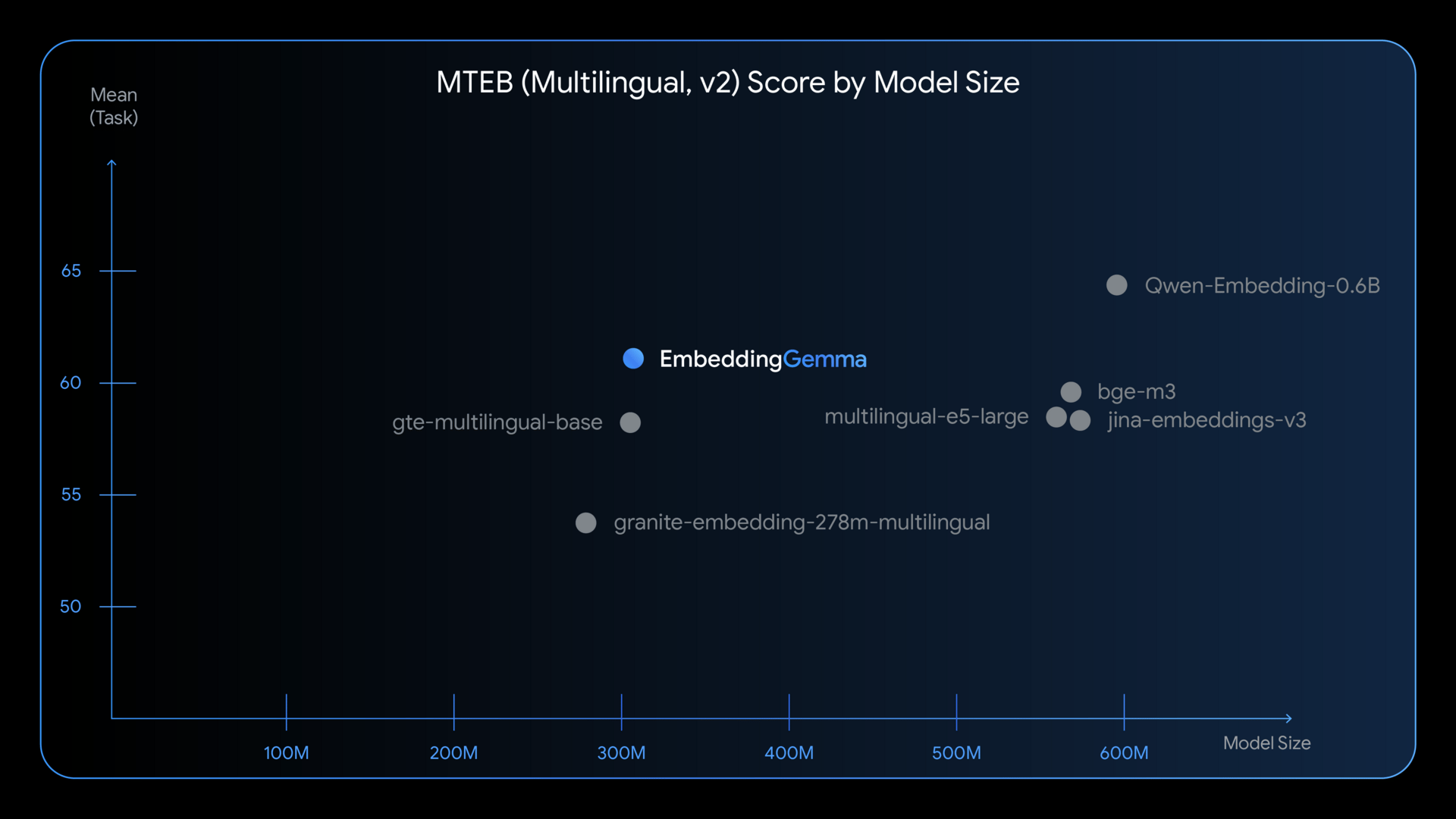
EmbeddingGemma: Google lanza el modelo de embeddings más eficiente para dispositivos
Google ha presentado EmbeddingGemma, un modelo abierto de 308M parámetros diseñado para llevar a móviles, portátiles y hardware local capacidades avanzadas de RAG (Retrieval Augmented Generation) y búsqueda semántica, con calidad y privacidad.
🔑 Puntos clave
Máxima calidad en su categoría: EmbeddingGemma es el modelo multilingüe de embeddings más preciso por debajo de 500M parámetros según el benchmark MTEB, con soporte para 100+ idiomas.
Optimizado para dispositivos: Corre con menos de 200MB de RAM (usando cuantización), ofrece inferencias en <15ms y permite reducir dimensiones de embeddings (768→128) con Matryoshka Representation Learning.
Uso offline y privado: Pensado para funcionar sin conexión, protege datos sensibles y habilita casos como búsqueda en archivos personales, chatbots locales y clasificación de consultas en móviles.
Integración sencilla: Ya es compatible con frameworks populares (sentence-transformers, LangChain, llama.cpp, Ollama, LMStudio, etc.), con ejemplos y guías disponibles.
Complemento de Gemma 3n: Combinado con este modelo generativo, permite construir pipelines RAG móviles que recuperan y generan respuestas en tiempo real.
🎯 Relevancia
EmbeddingGemma marca un paso hacia la IA móvil, privada y desconectada de la nube, acercando a usuarios y desarrolladores la posibilidad de ejecutar búsquedas semánticas y RAG de alta calidad directamente en sus dispositivos.
Qwen3-Max: el salto de Alibaba al club del billón de parámetros
Alibaba ha presentado Qwen3-Max, su modelo más grande hasta la fecha, con más de 1 billón de parámetros. Llega en fase preview, disponible en Qwen Chat y en la API de Alibaba Cloud.
🔑 Claves del anuncio
📊 Más capacidad y precisión: supera a Qwen3-235B en matemáticas, lógica, ciencia y programación. También sigue mejor las instrucciones y reduce alucinaciones.
🧩 Arquitectura Mixture of Experts: solo una fracción de parámetros se activa en cada token, lo que permite mayor potencia sin multiplicar el coste computacional.
📖 Contexto masivo: hasta 262K tokens de ventana de entrada y 32K de salida, ideal para documentos largos, bases de código completas y agentes que requieren memoria extendida.
🔍 Optimizado para RAG y llamadas a herramientas: no está pensado como un modelo de razonamiento, pero en pruebas internas mostró respuestas paso a paso muy similares a los sistemas especializados en esta tarea.
💲 Precios escalonados: desde $0.861/millón de tokens de entrada (para prompts de hasta 32K) hasta $2.151/millón en el rango más alto (128K–252K).
🗣️ Qwen3-ASR: Reconocimiento de voz multilingüe sin complicaciones
Alibaba presenta Qwen3-ASR, su nuevo modelo de transcripción de voz con altas prestaciones y soporte multilingüe.
🔑 Puntos clave
🧠 Reconocimiento automático de idioma y soporte para 11 lenguas (incluyendo español, inglés, chino, japonés y más).
🔊 Funciona con ruido de fondo, calidad baja, voces lejanas… ¡incluso con canciones o raps!
📝 Personalización en contexto: se le puede dar cualquier texto para mejorar la precisión con nombres raros, jerga o palabras inventadas.
📦 Todo en un solo modelo universal, ideal para aplicaciones en educación, medios, atención al cliente y más.
🚀 Kimi K2-0905: más contexto, mejor código y precisión total en herramientas
Kimi.ai lanza la actualización K2-0905 de su modelo Kimi K2, con mejoras clave para desarrolladores y agentes:
🔧 Novedades destacadas
💻 Mejora notable en programación front-end y llamadas a herramientas
🧠 Contexto ampliado a 256K tokens, ideal para proyectos grandes
🤖 Mayor integración con frameworks de agentes como Claude Code, Roo Code y otros
⚡ Turbo API disponible con 60–100 TPS y 100 % de precisión en llamadas a herramientas

Meta presenta REFRAG: velocidad y escala sin pérdidas en LLMs
Meta Superintelligence Labs acaba de anunciar REFRAG, un framework que promete revolucionar cómo los modelos de lenguaje manejan grandes volúmenes de contexto.
🔑 Claves del avance
30x más rápido: REFRAG evita el cálculo inútil sobre texto recuperado que no aporta valor en sistemas RAG, acelerando las respuestas sin sacrificar precisión.
16x más contexto: Los modelos pueden procesar documentos y conversaciones mucho más largos, ampliando la ventana de atención sin comprometer rendimiento.
Sin pérdida de exactitud: A pesar de los incrementos en velocidad y escala, las pruebas muestran que la calidad de las respuestas se mantiene estable.
🎯 Por qué importa
Este enfoque puede redefinir el estándar de eficiencia en la industria, permitiendo LLMs más rápidos, escalables y prácticos para aplicaciones críticas como RAG, análisis documental y agentes conversacionales de próxima generación.
Los modelos de lenguaje pequeños son el futuro de la IA agéntica, según un nuevo paper
Un reciente estudio propone que los Small Language Models (SLMs) no sólo son viables, sino más adecuados que los modelos gigantes para la mayoría de aplicaciones agénticas.
🔑 Claves del paper
Rendimiento sobresaliente: Phi-2 iguala el desempeño de modelos de 30B parámetros, funcionando 15x más rápido.
Costos drásticamente menores: Servir un SLM de 7B es 10–30x más barato que un modelo grande.
Ajuste fino para agentes: El fine-tuning en interacciones estructuradas (como llamadas a herramientas) asegura precisión y consistencia.
Sistemas heterogéneos: Los SLM manejan tareas rutinarias, mientras que los LLM se reservan para pasos complejos.
Privacidad y latencia: Ejecutar SLMs en dispositivo reduce tiempos de respuesta y protege los datos sensibles.
🎯 Por qué importa
El paper sugiere un cambio de paradigma: la eficiencia y especialización de los SLMs puede impulsar la expansión real de la IA agéntica, relegando los modelos masivos a un rol de soporte estratégico.
Robots
NOMAD: el nuevo UGV autónomo de Scout AI y Hendrick Motorsports
Scout AI se ha unido a Hendrick Motorsports Technical Solutions para lanzar NOMAD, un vehículo terrestre no tripulado (UGV) automatizado por su nueva plataforma Fury, diseñada para operaciones de defensa.
🔑 Claves del anuncio
Hardware rediseñado: Fury incorpora un stack de cómputo totalmente renovado, 90% más pequeño y eficiente que la versión anterior. Utiliza sólo cámaras, sin necesidad de calibración ni LiDAR.
Modelo fundacional ligero: Scout AI presenta un nuevo modelo optimizado para inferencia rápida en plataformas pequeñas, con un número de parámetros reducido y adaptado a entornos de baja capacidad de cómputo.
Adaptación ultrarrápida: Fury se ajustó a este nuevo vehículo en solo unas horas de datos de entrenamiento, reutilizando su conocimiento previo de conducción en tierra y aprendiendo únicamente las características específicas de este robot.
🎯 Por qué importa
Este avance muestra cómo los modelos fundacionales especializados y eficientes pueden acelerar la adopción de vehículos autónomos en defensa y seguridad, ampliando la extensibilidad y portabilidad de la IA a múltiples plataformas en tiempo récord.
Scout and Hendrick Motorsports Technical Solutions today announced a partnership on NOMAD, HMS’s next-generation UGV controlled by Scout’s Fury autonomy system
NOMAD represents Fury’s second UGV form factor and debuts Scout’s fastest foundation model to date, lightweight,
— Scout AI (@ScoutAI_)
10:03 AM • Sep 2, 2025
RAI: Un robot que hace mountain bike
El RAI Institute ha presentado un robot con capacidades de ciclismo de montaña a nivel competitivo, capaz de saltar, girar y mantener el equilibrio en terrenos irregulares gracias a aprendizaje por refuerzo y una mecánica personalizada.
Su vehículo, llamado Ultra Mobility Vehicle, combina eficiencia de ruedas con habilidades de salto similares a las de una pierna, llevando la movilidad robótica más allá de los límites tradicionales.
Using reinforcement learning we have expanded the range of techniques the Ultra Mobile Vehicle (UMV) uses to handle terrain and obstacles, including hops, out-of-plane balance, and level-ground flips. Millions of physics-based simulations provide training data to support
— RAI Institute (@rai_inst)
3:15 PM • Sep 3, 2025
RoboBallet: DeepMind enseña a los robots a coordinarse como un ballet
Google DeepMind, en colaboración con Intrinsic AI y UCL, presenta RoboBallet, un sistema de IA capaz de coordinar hasta 8 brazos robóticos con precisión milimétrica, sin colisiones.
🧠 Entrenado con aprendizaje por refuerzo, RoboBallet aprende principios generales de planificación de tareas y movimiento, generando planes eficientes para nuevos flujos de trabajo en segundos.
🚀 Supera a métodos tradicionales en un ~25% de eficiencia, y apunta a revolucionar las líneas de producción adaptativas del futuro.
Our AI system RoboBallet can choreograph a team of robot arms with precision, working together without collisions. 🤖
Developed with @IntrinsicAI and @ucl, it can automate task and motion planning for up to 8 robots at a time - outperforming traditional methods by ~25%.
— Google DeepMind (@GoogleDeepMind)
1:12 PM • Sep 8, 2025
Reflexiones Finales
Dario AmoDei: en 1-3 años que los modelos de IA podrían ir más allá de la frontera del conocimiento humano y las cosas podrían volverse locas
Dario Amodei believes in 1-3 years AI models could go beyond the frontier of human knowledge and things could go crazy!
— Rohan Paul (@rohanpaul_ai)
11:25 PM • Sep 6, 2025