- Best-IA Newsletter
- Posts
- Boletín Semanal Best-IA #122
Despedimos 2025, el año en que la IA dejó de limitarse a responder preguntas y empezó a actuar como agente: planificando, usando herramientas y ejecutando tareas reales en entornos productivos y creativos a escala global.
En Best-IA hacemos una pausa navideña de dos semanas para volver en 2026 y seguir analizando, sin ruido ni hype, cómo esta tecnología avanza a un ritmo que ya no da margen a la indiferencia.
Nos vemos en 2026. Feliz Navidad y próspero año nuevo.
Noticias
Gemini 3 Flash: Google acelera la IA general para tareas cotidianas
Google ha lanzado Gemini 3 Flash, su modelo gratuito optimizado para velocidad y eficiencia, que introduce una mejora significativa en rendimiento frente a versiones anteriores, manteniendo capacidades avanzadas de razonamiento multimodal.
🔑 Claves de Gemini 3 Flash
Velocidad sin sacrificar inteligencia
Optimizado para respuestas rápidas, supera en varios benchmarks incluso a Gemini 2.5 Pro, priorizando eficiencia y baja latencia.Trabajo con voz en tiempo real
Convierte notas de voz en planes de estudio, analiza exámenes orales y genera acciones concretas para mejorar el aprendizaje.Análisis multimodal ampliado
Resume y analiza vídeos cortos y documentos largos, incluso cuando el contenido está en distintos idiomas.De idea a app en minutos
Transforma pensamientos dictados en estructuras claras: apps funcionales, planes de proyecto o prototipos directamente en Canvas.Soporte para negocio y marketing
Ayuda a idear productos, diseñar estrategias go-to-market y crear landings a partir de encuestas de clientes en una sola conversación.Disponibilidad amplia y sin coste
Gemini 3 Flash ya está disponible en preview a través de la Gemini API en Google AI Studio, Google Antigravity, Vertex AI y Gemini Enterprise, además de herramientas para desarrolladores como Gemini CLI y Android Studio, y comienza su despliegue en la app de Gemini y el modo IA de Search.
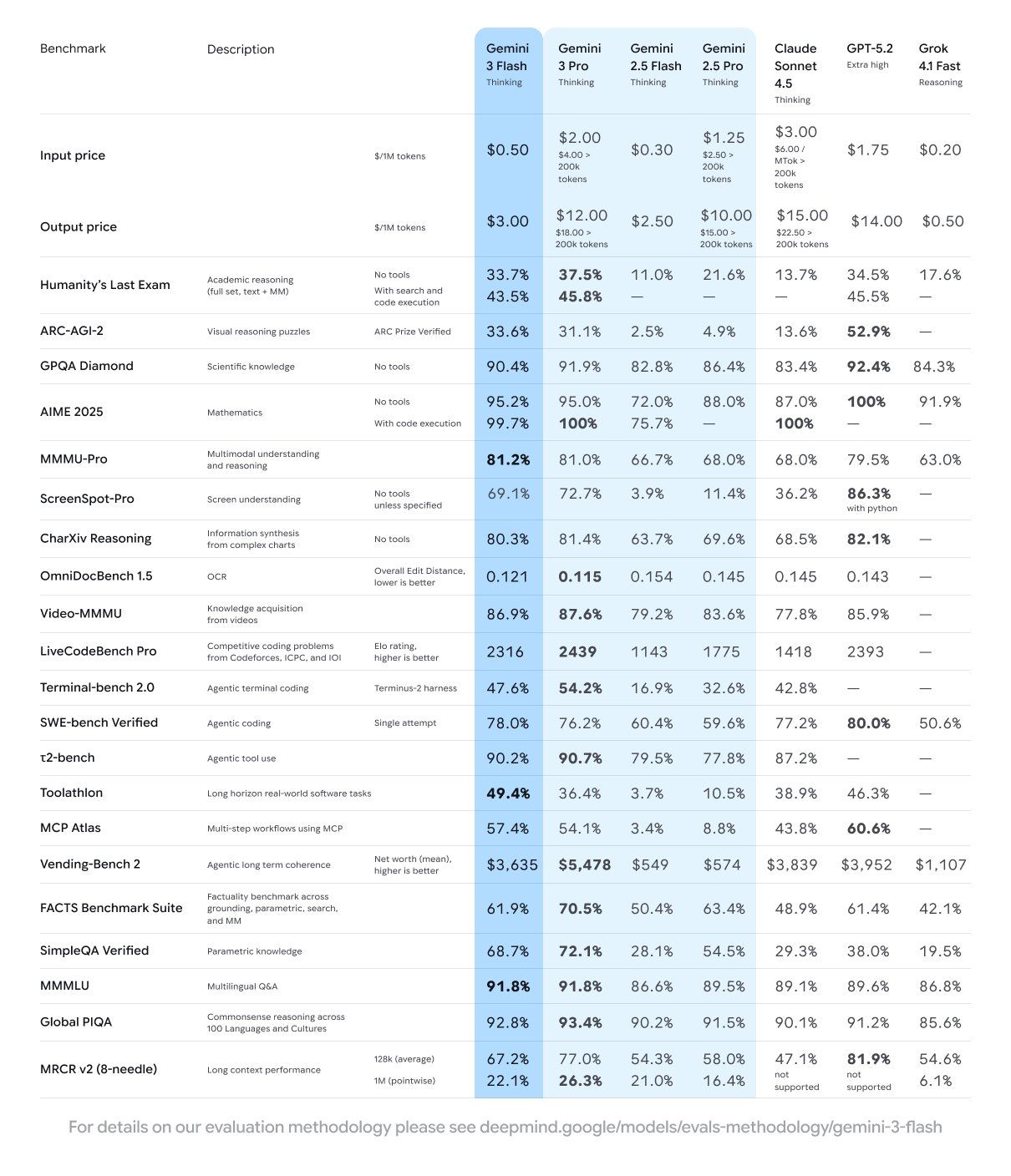
🎯 Gemini 3 Flash refuerza la tendencia hacia modelos generalistas rápidos y accesibles, orientados a productividad diaria, donde la baja latencia y la multimodalidad se vuelven tan importantes como el razonamiento avanzado.
Gemini 2.5 Flash Native Audio: mejoras clave para agentes de voz en tiempo real
Google DeepMind lanza una versión actualizada de Gemini 2.5 Flash Native Audio, su modelo orientado a agentes de voz en tiempo real. La actualización se centra en mejorar la comprensión de instrucciones y la naturalidad conversacional en escenarios interactivos.
Google presenta T5Gemma 2, una nueva generación de modelos encoder-decoder
Google ha lanzado T5Gemma 2, un modelo encoder-decoder compacto y de nueva generación basado en Gemma 3, disponible en tamaños de 270M, 1B y 4B. Destaca por ser multimodal, soportar largo contexto y funcionar en 140 idiomas, ofreciendo una alternativa potente a los modelos decoder-only dominantes y abriendo nuevas vías de experimentación para investigadores y desarrolladores.
OpenAI lanza ChatGPT Images con edición precisa y mayor fidelidad visual
OpenAI ha presentado ChatGPT Images, una nueva generación de modelos de imagen integrada directamente en ChatGPT y disponible vía API como GPT Image 1.5, con mejoras claras en control, velocidad y consistencia visual.
🔑 Claves del lanzamiento
Mejor seguimiento de instrucciones: el modelo interpreta con mayor precisión lo que se le pide y evita cambios no solicitados.
Edición avanzada y localizada: permite añadir, eliminar, combinar o transformar elementos sin alterar iluminación, composición o rasgos clave.
Preservación de detalles: mantiene coherencia visual entre iteraciones y ediciones sucesivas.
Rendimiento mejorado: genera imágenes hasta 4 veces más rápido que el modelo anterior.
Nueva interfaz dedicada: ChatGPT incorpora una sección específica de Images para trabajar directamente con generación y edición visual.
🎯 Este avance refuerza la convergencia entre modelos multimodales y herramientas creativas profesionales, acercando la generación de imágenes a flujos de trabajo reales donde el control fino y la coherencia son tan importantes como la creatividad.
GPT-5.2-Codex: salto en programación agente y ciberseguridad
OpenAI presenta GPT-5.2-Codex, su modelo más avanzado para programación agente, diseñado para afrontar tareas reales de ingeniería de software con mayor fiabilidad, contexto extendido y mejor uso de herramientas.
🔑 Puntos clave
Programación agente avanzada: mejora en comprensión de largo contexto, compacción nativa y llamadas a herramientas, facilitando flujos complejos de desarrollo y uso de terminal.
Rendimiento líder: estado del arte en benchmarks como SWE-Bench Pro y Terminal-Bench 2.0, superando a generaciones Codex anteriores.
Soporte oficial para skills: Codex ya admite skills: paquetes reutilizables de instrucciones, scripts y recursos que le ayudan a completar tareas concretas. Pueden invocarse directamente con
$.skill-nameo dejar que Codex seleccione automáticamente la más adecuada según el prompt.Mayor capacidad en ciberseguridad: demuestra utilidad práctica en detección de vulnerabilidades; investigadores ya han identificado fallos reales usando modelos previos.
Gestión de riesgos: OpenAI reconoce el carácter de doble uso y opta por un despliegue gradual, con accesos controlados para equipos defensivos.
Disponibilidad: ya accesible en Codex para usuarios de pago de ChatGPT; la API llegará próximamente.
🎯 Este avance consolida la tendencia hacia modelos agentes capaces de intervenir en sistemas reales. Aumenta la productividad y la defensa digital, pero obliga a equilibrar potencia y control en el despliegue de IA avanzada.
ChatGPT estrena directorio de apps integradas
OpenAI ha añadido un directorio de aplicaciones en ChatGPT que permite explorar y añadir apps aprobadas según plan y región. Los conectores pasan a mostrarse como apps, y los desarrolladores ya pueden enviar las suyas para revisión y publicación.
Black Forest Labs presenta FLUX.2 [max], su modelo visual más avanzado hasta la fecha
Black Forest Labs ha lanzado FLUX.2 [max], su modelo de generación y edición de imágenes de mayor calidad, orientado a flujos creativos profesionales y a la creación de imágenes consistentes, contextualizadas y listas para producción.
🔑 Claves del lanzamiento
Grounded Generation con búsqueda web: el modelo puede consultar información en tiempo real para generar imágenes con contexto actual, desde resultados deportivos hasta eventos históricos con mayor precisión.
Consistencia visual avanzada: admite hasta 10 imágenes de referencia, manteniendo coherencia en productos, personajes y estilos.
Alto rendimiento técnico: se sitúa en el puesto #2 en Artificial Analysis en tareas de text-to-image y edición de imágenes.
Orientado a marketing y e-commerce: genera imágenes de producto pulidas y coherentes, preparadas para catálogos y marketplaces.
Estética cinematográfica: diseñado para cineastas y creativos, con texturas ricas y frames estilizados ideales para concept art y storyboards.
🎯 FLUX.2 [max] refuerza la tendencia hacia modelos visuales conectados a datos en tiempo real y orientados a producción, donde la coherencia, el contexto dinámico y la calidad estética definen la nueva generación de herramientas creativas basadas en IA.
Pruébalo en https://playground.bfl.ai/image/generate
Tencent abre HY World 1.5 y da un salto en modelos de mundo interactivos
Tencent ha liberado HY World 1.5 (WorldPlay), un framework open-source para modelado de mundos en tiempo real que permite generar y explorar entornos 3D interactivos a partir de texto o imágenes, con coherencia geométrica sostenida.
🔑 Claves del avance
Generación en tiempo real: streaming de vídeo de largo horizonte a 24 FPS, manteniendo estabilidad visual durante la exploración.
Consistencia geométrica prolongada: incorpora Reconstituted Context Memory, que reconstruye dinámicamente el contexto de frames pasados y reduce la pérdida de memoria.
Control interactivo robusto: sistema de Dual Action Representation que responde de forma fiable a entradas de teclado y ratón.
Exploración tipo videojuego: posibilidad de caminar, mirar alrededor e interactuar en mundos 3D generados.
Aplicaciones flexibles: soporta perspectivas en primera y tercera persona, eventos guiados por prompt y expansión infinita del entorno.
🎯 HY World 1.5 consolida los modelos de mundo como núcleo de la IA encarnada, acercando simulación, interacción y generación continua, base para agentes autónomos, videojuegos generativos y entrenamiento de robots en entornos virtuales persistentes.
Alibaba presenta Wan 2.6: vídeo y narrativa multimodal de nivel cinematográfico
Alibaba ha lanzado Wan 2.6, una nueva generación de modelo multimodal nativo capaz de generar vídeos e imágenes de alta calidad combinando narrativa estructurada, consistencia audiovisual y control creativo avanzado desde prompts simples.
🔑 Claves de Wan 2.6
Casting y consistencia de personajes
Permite reutilizar personajes de vídeos de referencia en nuevas escenas, manteniendo apariencia y voz, incluso en interacciones complejas entre varias personas y objetos.Narrativa multi-plano inteligente
Convierte prompts simples en vídeos con múltiples planos auto-storyboardizados, manteniendo coherencia visual y narrativa más allá de tomas aisladas.Sincronización nativa audio-vídeo
Genera diálogos entre varios hablantes con lip-sync natural y audio de calidad de estudio, integrando voz y movimiento desde el modelo base.Calidad cinematográfica
Producción de vídeos de hasta 15 segundos en 1080p, con mejoras en física del movimiento, seguimiento de instrucciones y control estético.Síntesis y edición de imagen avanzada
Ofrece fotorrealismo con control preciso de lente e iluminación, soportando múltiples imágenes de referencia para resultados coherentes a nivel comercial.
🎯 Wan 2.6 refleja la evolución hacia modelos multimodales que integran imagen, vídeo, audio y razonamiento narrativo, acercando la generación audiovisual automatizada a flujos profesionales de cine, publicidad y creación de contenidos complejos.
Pruébalo en https://wan.video/
Qwen-Image-Layered: imágenes generativas con capas nativas editables
Qwen ha lanzado Qwen-Image-Layered, un modelo open-source que permite descomponer imágenes generadas en capas RGBA reales, controlables por prompt. El sistema ofrece edición estructural avanzada, con descomposición jerárquica y control preciso del nivel de detalle.
ResembleAI desafía a ElevenLabs con TTS open-source en tiempo real y audio verificable
ResembleAI ha presentado Chatterbox Turbo, un modelo de texto a voz open-source que combina baja latencia, alta calidad expresiva y autenticación integrada, cuestionando el dominio de soluciones propietarias como ElevenLabs.
🔑 Claves de Chatterbox Turbo
Latencia ultrabaja
Tiempo hasta el primer sonido inferior a 150 ms, adecuado para aplicaciones en tiempo real.Calidad y expresividad avanzadas
Supera a modelos propietarios más grandes, con soporte sólido para etiquetas paralingüísticas y expresiones humanas naturales.Clonación de voz zero-shot
Replica voces con solo 5 segundos de audio, sin procesos de verificación complejos.Autenticidad integrada
Incluye PerTh watermarking, permitiendo audio autenticado y verificable desde el diseño del modelo.Open-source y transparente
Código abierto, sin cajas negras, facilitando auditoría, personalización y adopción amplia.
🎯 Este avance señala una tendencia clave en IA de voz: modelos abiertos que igualan o superan a los propietarios, integrando rendimiento, expresividad y seguridad, y redefiniendo estándares para TTS en producción y tiempo real.
Manus 1.6: agentes más autónomos y salto real hacia la creación end-to-end
Manus lanza la versión 1.6 con una actualización profunda de su arquitectura de agentes. El objetivo es claro: ejecutar tareas más complejas con menos supervisión humana y reducir la distancia entre dar instrucciones y obtener resultados funcionales.
🔑 Claves del lanzamiento
Manus 1.6 Max como nuevo agente insignia: mejora significativa en tasas de éxito, menor necesidad de supervisión y un aumento del 19,2 % en satisfacción de usuarios según benchmarks internos orientados a escenarios reales.
Mejor rendimiento en tareas complejas: los tests muestran avances especialmente relevantes en flujos largos, con múltiples pasos y dependencias.
Desarrollo de apps móviles end-to-end: basta con describir la aplicación para que Manus gestione diseño, lógica y construcción completa del producto.
Design View interactivo: nueva interfaz visual que permite editar imágenes directamente sobre un lienzo activo (colores, texto, composición) mediante interacción directa, sin prompts intermedios.
🎯 Manus 1.6 refuerza la tendencia hacia agentes más autónomos, capaces de ejecutar flujos completos sin microgestión. Es un paso coherente con la evolución de la IA generativa hacia sistemas que no sólo responden, sino que construyen productos funcionales.
En breve
Grok activa la cámara y la voz como interfaz de inteligencia visual
Grok convierte la cámara del móvil en una herramienta de comprensión visual y lanza su Voice Agent API para conversaciones en tiempo real. Visión + voz permiten explicar imágenes al instante y crear asistentes y agentes telefónicos multilingües con baja latencia y voces naturales.
ElevenLabs integra WhatsApp en sus agentes de voz y chat
ElevenLabs amplía su plataforma omnicanal con soporte nativo para WhatsApp, permitiendo diseñar un agente una sola vez y desplegarlo en web, móvil, líneas telefónicas y mensajería, sin duplicar flujos ni lógica.
SAM Audio: aislamiento de sonido multimodal en un único modelo
Meta ha lanzado SAM Audio, el primer modelo unificado capaz de aislar cualquier sonido dentro de mezclas de audio complejas usando prompts de texto, señales visuales o fragmentos temporales, ampliando radicalmente las posibilidades creativas y de análisis sonoro.
Claude llega a Chrome y refuerza Claude Code
Anthropic lanza Claude como extensión en Chrome a todos los planes de pago e integra Claude Code, que suma resaltado de sintaxis en diffs, sugerencias de prompts, marketplace de plugins oficiales y pases de invitado compartibles para colaboración.
Mistral OCR 3: nuevo salto en inteligencia documental
Mistral AI lanza Mistral OCR 3, una evolución significativa en procesamiento inteligente de documentos. El modelo establece nuevos estándares de precisión y eficiencia, superando tanto a soluciones OCR empresariales clásicas como a alternativas OCR basadas en IA.
Robots
LimX Dynamics TRON 2: una plataforma modular para robótica avanzada
TRON 2 es el nuevo robot modular de LimX Dynamics orientado a investigación y desarrollo en robótica e IA embodied. Su diseño permite múltiples configuraciones de movilidad y manipulación, sirviendo como base flexible para experimentar con control, percepción y autonomía en entornos reales.
Reflexiones Finales
The future of intelligence | Demis Hassabis (Co-founder and CEO of DeepMind)
Hassabis expone que para llegar a AGI hará falta combinar escala + innovación, y el siguiente salto real pasa por agentes y “world models” (simulación) para ganar consistencia, fiabilidad y acción en el mundo.