- Best-IA Newsletter
- Posts
- Boletín Semanal Best-IA #126
Tutoriales
La conexión que faltaba: NotebookLM + Antigravity
7 MCP que mejoran tu IA para programar
Noticias
Project Genie: Google lleva la IA generativa a mundos 3D interactivos en tiempo real
Project Genie ha lanzado su plataforma para crear y explorar mundos tridimensionales interactivos a partir de texto o imágenes. Basada en modelos avanzados de Google, amplía la IA generativa más allá de contenido estático hacia entornos navegables y dinámicos.
🔑 Claves del proyecto
Generación de mundos en tiempo real: A diferencia de imágenes o vídeos, los entornos se crean dinámicamente mientras el usuario se mueve e interactúa, incorporando navegación y simulación básica.
World model Genie 3: El sistema se apoya en Genie 3, desarrollado por Google DeepMind, especializado en generar espacios coherentes a partir de descripciones.
Entrada multimodal: Los mundos pueden originarse tanto desde texto como desde imágenes, que sirven como referencia inicial del entorno.
Interactividad y remix: Incluye objetos y personajes reactivos, además de la posibilidad de remezclar mundos existentes para crear variaciones.
Acceso limitado: Disponible como prototipo para suscriptores de Google AI Ultra en EE. UU., con despliegue progresivo previsto.
🎯 Project Genie apunta a una nueva fase de la IA generativa: modelos que no sólo describen o representan el mundo, sino que lo simulan y lo hacen explorable, acercando la creación de experiencias interactivas a usuarios sin conocimientos técnicos avanzados.
Google Chrome se actualiza con Gemini 3 para una navegación más inteligente
Google ha lanzado una actualización importante de Google Chrome que integra Gemini 3 para mejorar la experiencia de navegación. Incluye un side panel para multitarea, Nano Banana para transformar imágenes en la web, más integraciones con apps de Google, ayuda más contextual y un auto browse preview para usuarios Google AI Pro y Ultra que automatiza tareas de varios pasos.
Agentic Vision en Gemini 3 Flash: la visión como proceso agente
Agentic Vision es una nueva capacidad de Gemini 3 Flash con la que Google AI convierte la comprensión visual en un proceso iterativo y agente. En lugar de analizar imágenes en un solo paso, el modelo razona, actúa sobre la imagen mediante código y vuelve a observar, mejorando la verificación, la trazabilidad y el control en tareas visuales complejas.
Google DeepMind libera los pesos de AlphaGenome
Google DeepMind ha anunciado la liberación de los pesos de AlphaGenome, su modelo de secuencia de ADN diseñado para predecir el impacto molecular de cambios genéticos y acelerar nuevos descubrimientos biológicos.
OpenAI Prism: un workspace científico colaborativo con GPT-5.2 integrado
OpenAI Prism es un entorno de trabajo científico gratuito, en la nube y nativo en LaTeX, diseñado para escribir y colaborar en papers con asistencia directa de GPT-5.2 integrada dentro del propio documento.
🔑 Claves de Prism
LaTeX nativo y cloud-based: Editor sin fricción técnica ni configuración local, pensado para flujos reales de investigación.
IA dentro del paper: GPT-5.2 opera con acceso al contexto completo del documento: estructura, ecuaciones, referencias y secciones adyacentes.
Colaboración sin límites: Proyectos y colaboradores ilimitados, con control de versiones integrado y sin conflictos manuales.
Asistencia contextual real: La IA actúa como copiloto de escritura científica, no como chat externo desconectado del trabajo.
Disponibilidad inmediata: Acceso abierto para cuentas personales de ChatGPT, con expansión prevista a planes Business, Team, Enterprise y Education.
🎯 Prism refuerza el giro de OpenAI hacia plataformas científicas verticales, integrando la IA directamente en la producción de conocimiento y reduciendo barreras técnicas, aunque plantea retos de dependencia, propiedad intelectual y validación científica externa.
LINK: https://prism.openai.com
ChatGPT Apps acelera como plataforma: más de 60 apps aprobadas en una semana
OpenAI ha anunciado que más de 60 apps de ChatGPT han sido aprobadas en una sola semana. El despliegue sigue una cadencia continua, con nuevas incorporaciones previstas, y consolida a ChatGPT como plataforma al integrar las apps como experiencias nativas, no como simples enlaces externos.
Anthropic amplía Claude Cowork con 11 plugins open-source
Anthropic ha lanzado 11 plugins open-source para Claude Cowork que permiten personalizar flujos de trabajo en ventas, finanzas, legal, datos, marketing y soporte. Funcionan como paquetes modulares de skills y conectores, orientados a automatización local y configurables incluso por equipos no técnicos, en research preview.
Anthropic impulsa Generative UI con MCP Apps: agentes que controlan la interfaz
Anthropic ha lanzado esta semana MCP Apps, habilitando una nueva clase de aplicaciones basadas en Generative UI, donde los agentes no solo conversan, sino que deciden qué interfaz mostrar. El enfoque separa intención (definida por el agente mediante especificaciones como A2UI y MCP-UI) de renderizado (controlado por la app), usando AG-UI como capa de comunicación. Frameworks como CopilotKit y VS Code ya permiten implementar este paradigma end-to-end.
Claude in Excel llega a los planes Pro
Anthropic ha habilitado Claude in Excel para usuarios Pro. La integración admite múltiples archivos por drag & drop, evita sobrescribir celdas existentes y gestiona sesiones largas con auto-compaction, mejorando la fiabilidad del trabajo directo sobre hojas de cálculo.
Kimi K2.5: inteligencia agentic visual open-weights más cerca del frontier
Moonshot AI ha presentado Kimi K2.5, su nuevo modelo open-source de inteligencia agentic visual, que consolida a Kimi como el líder entre los modelos de pesos abiertos y lo sitúa a corta distancia de los grandes laboratorios cerrados.
🔑 Claves de Kimi K2.5
SOTA en tareas agentic: Lidera benchmarks agentic como HLE (50,2 %) y BrowseComp (74,9 %). En GDPval-AA alcanza un Elo de 1309, solo por detrás de modelos de OpenAI y Anthropic, superando a GLM-4.7, DeepSeek V3.2 y Gemini 3 Pro.
Multimodalidad nativa: Primer modelo flagship open-weights con soporte completo para imagen y vídeo. Logra 78,5 % en MMMU Pro y 86,6 % en VideoMMMU, eliminando una barrera histórica frente a modelos propietarios.
Agent Swarm (beta): Permite ejecutar hasta 100 sub-agentes en paralelo, con 1.500 llamadas a herramientas y hasta 4,5× más velocidad frente a configuraciones mono-agente.
Código y creatividad: Orientado a coding with taste, capaz de transformar texto, imágenes y vídeo en sitios web con animación y diseño expresivo.
Coste y rendimiento: Velocidad por defecto de 60–100 tok/s, con precios de entrada un 50 % más bajos que K2 Turbo y en torno al 20 % del coste de Claude Opus 4.5.
Menos alucinaciones: Mejora clara en el índice AA-Omniscience, con menor tendencia a fabricar respuestas frente a versiones previas.

🎯 Kimi K2.5 confirma que los modelos open-weights ya no solo compiten en benchmarks clásicos, sino también en razonamiento agentic, multimodalidad y costes operativos. Es un paso estructural que acerca el ecosistema abierto al frontier, reduciendo la brecha con OpenAI, Anthropic y Google, y reforzando la viabilidad de agentes avanzados en producción real.
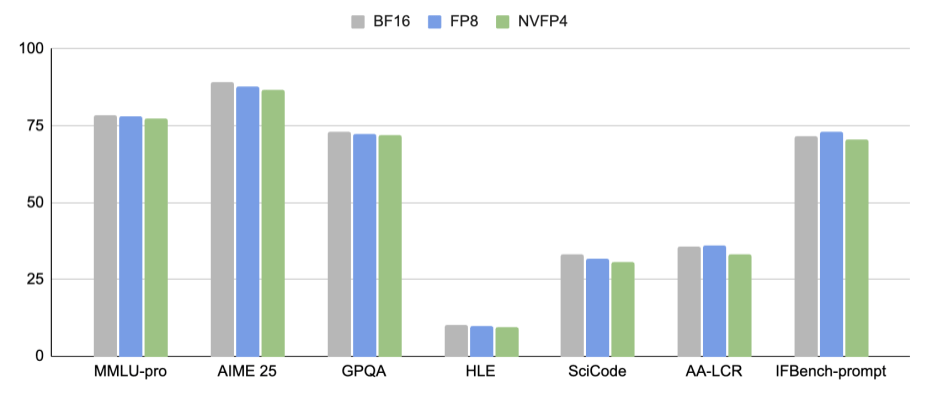
NVIDIA Nemotron 3 Nano NVFP4: cuantización extrema con precisión casi BF16
NVIDIA ha presentado Nemotron 3 Nano NVFP4, una nueva variante ultra-eficiente de su modelo híbrido MoE de 30B parámetros, basada en la precisión numérica NVFP4 para reducir coste computacional sin perder calidad relevante.
🔑 Claves técnicas
Nueva precisión NVFP4: Cuantiza pesos y activaciones a FP4, logrando hasta 4× más FLOPS frente a BF16 y 1,7× menos memoria que FP8.
Precisión preservada: Mantiene hasta el 99,4 % de la calidad BF16 gracias a Quantization-Aware Distillation (QAD).
Modelo + hardware co-diseñados: Optimizado para GPUs Blackwell (B200), con beneficios también en GPUs de consumo como RTX 5090.
Inferencia más accesible: Facilita despliegues locales y edge de modelos grandes con requisitos mucho menores.
NVIDIA Earth-2 Nowcasting supera a modelos físicos en predicción a corto plazo
NVIDIA ha presentado Earth-2 Nowcasting, impulsado por StormScope, un sistema de IA generativa capaz de producir predicciones meteorológicas a escala país y resolución kilométrica (0–6 horas) en minutos. Es el primer enfoque que supera a modelos físicos tradicionales en short-term precipitation forecasting, simulando dinámicas de tormentas y prediciendo directamente imágenes de satélite y radar.
Tencent HunyuanImage 3.0-Instruct: edición de imágenes multimodal con razonamiento nativo
Tencent HunyuanImage 3.0-Instruct es un modelo multimodal nativo centrado en edición de imágenes con razonamiento, que integra comprensión visual profunda y síntesis de alta fidelidad en un único sistema.
🔑 Claves del modelo
Modelo “thinking” con CoT nativo: Incorpora Chain-of-Thought interno reforzado por el algoritmo propietario MixGRPO, permitiendo razonar instrucciones complejas antes de generar la imagen.
Edición precisa sin degradación: Permite añadir, eliminar o modificar elementos manteniendo intactas las áreas no objetivo, uno de los puntos más exigentes en image editing.
Fusión multi-imagen avanzada: Extrae y combina elementos de múltiples imágenes en escenas coherentes y consistentes.
Rendimiento SOTA: Tencent afirma una calidad visual y alineación con intención humana comparable a modelos propietarios líderes.
🎯 HunyuanImage 3.0-Instruct refuerza la tendencia hacia modelos visuales que razonan antes de generar, acercando la edición de imágenes a un paradigma agentic y multimodal. Es un avance estructural para flujos creativos y de diseño, y consolida la competencia real de modelos abiertos chinos frente al frontier propietario.
Qwen3-Max-Thinking: el nuevo modelo de razonamiento de Qwen con uso adaptativo de herramientas
Qwen ha presentado Qwen3-Max-Thinking, su modelo de razonamiento más capaz hasta la fecha, entrenado a gran escala con RL y orientado a tareas de reasoning, conocimiento, uso de herramientas y capacidades agentic.
🔑 Claves
Tool-use adaptativo: el modelo decide cuándo usar Search, Memory y Code Interpreter sin selección manual, combinándolos dentro del mismo flujo de respuesta.
Test-time scaling: incorpora auto-reflexión multi-ronda en inferencia para mejorar resultados de razonamiento, destacando comparativas favorables frente a Gemini 3 Pro en tareas de reasoning según el anuncio.
Benchmarks reportados: rendimiento alto en matemáticas (HMMT Feb 98,0) y en agentic search (HLE con tools 49,8).
Disponibilidad: ya está accesible en chat/agent mode en Qwen Chat.

🎯 Qwen3-Max-Thinking empuja el estándar “modelo + herramientas” hacia una experiencia más autónoma: menos orquestación manual y más bucles de verificación. Si escala en producto, sube el listón para agentes útiles en trabajo real.
Robots
Helix 02: autonomía corporal completa en robots humanoides
Figure ha presentado Helix 02, su modelo más avanzado hasta la fecha, diseñado para ejecutar tareas domésticas complejas de principio a fin mediante control autónomo de todo el cuerpo, sin teleoperación ni secuencias preprogramadas.
🔑 Claves del anuncio
Autonomía de cuerpo completo: Helix 02 coordina locomoción, manipulación y percepción para realizar tareas largas y continuas, como fregar platos, sin intervención humana.
Nueva arquitectura jerárquica: Amplía el enfoque System 1 / System 2 con un nuevo System 0, integrando el control desde píxeles y sensores hasta par y fuerza en cada articulación.
Manipulación avanzada: Incorpora sensores táctiles y cámaras en las palmas, lo que permite tareas de destreza fina más allá de la visión pura.
Enfoque en entornos reales: El modelo está optimizado para escenarios domésticos no estructurados, uno de los grandes retos de la robótica humanoide.
🎯 Helix 02 refuerza la tendencia hacia robots generalistas capaces de aprender y ejecutar tareas complejas en el mundo físico, acercando la robótica humanoide a aplicaciones reales y escalables fuera del laboratorio.
NVIDIA GR00T N1.6: simulación para escalar la robótica humanoide
NVIDIA ha presentado GR00T N1.6, un modelo abierto vision-language-action preentrenado con datos sintéticos a gran escala, incluyendo miles de horas de simulación BEHAVIOR de Stanford SVL. El enfoque reduce la dependencia de datos reales costosos y mejora la adaptabilidad sim-to-real y la generalización entre distintos robots.