- Best-IA Newsletter
- Posts
- Boletín Semanal Best-IA #71
Tutoriales
30 trucos de ChatGPT que debes conocer en 2024
Noticias
Open AI
Canvas mejorado con ejecución de código y más funcionalidades
Canvas ya está disponible en 4o para todos los usuarios (gratis y de pago) Ahora puedes ejecutar código Python, obtener sugerencias específicas e importar fácilmente tu propia escritura y código.
Nueva función “Proyectos”
OpenAI lanza la función "Projects" en ChatGPT, que permite a los usuarios subir archivos, organizar conversaciones y establecer instrucciones personalizadas en espacios de trabajo tipo carpetas, disponible para usuarios Plus, Pro y Teams. Esta función incluye gestión de archivos, organización de conversaciones e instrucciones personalizadas, con soporte para Canvas y búsqueda web. Además, mejora los flujos de trabajo de desarrollo y codificación al permitir la carga de archivos completos de documentación, facilitando sesiones de chat más enfocadas y organizadas.
Modo de Voz Avanzado con Visión
OpenAI ha lanzado el Modo de Voz Avanzado con Visión, permitiendo a los usuarios de ChatGPT Plus, Team y Pro interactuar en tiempo real con objetos usando la cámara del móvil y hacer preguntas sobre lo que ven en su pantalla.
La disponibilidad no es universal, ya que algunos usuarios, como los de la UE, no la recibirán aún, y los de Enterprise y Edu hasta enero.
Este lanzamiento ocurre en medio de la competencia con Google Gemini 2.0, que también ofrece capacidades de análisis visual y auditivo en tiempo real.
OpenAI lanza su Esperada Herramienta de Creación de Videos “Sora”, pero no estará disponible en la UE ni UK por ahora
OpenAI ha lanzado Sora, su modelo para generación y edición de videos a partir de texto, imágenes o clips preexistentes, pero no estará disponible en la UE ni UK por ahora.
Puntos Clave:
Funciones Creativas y Flexibles
Sora incluye herramientas avanzadas como Remix para transformar ideas en contenido visual, Re-cut para completar escenas optimizando fotogramas, y Storyboard para organizar y editar secuencias en una línea de tiempo personal. Además, permite crear loops perfectos, fusionar videos con Blend y aplicar estilos personalizados mediante Style Presets.Opciones de Suscripción
Sora está disponible en los planes ChatGPT Plus ($20/mes) y ChatGPT Pro ($200/mes). El plan Plus ofrece hasta 50 videos prioritarios en resolución 720p, mientras que el plan Pro incluye hasta 500 videos prioritarios, generación sin límites, resolución 1080p y descargas sin marcas de agua.
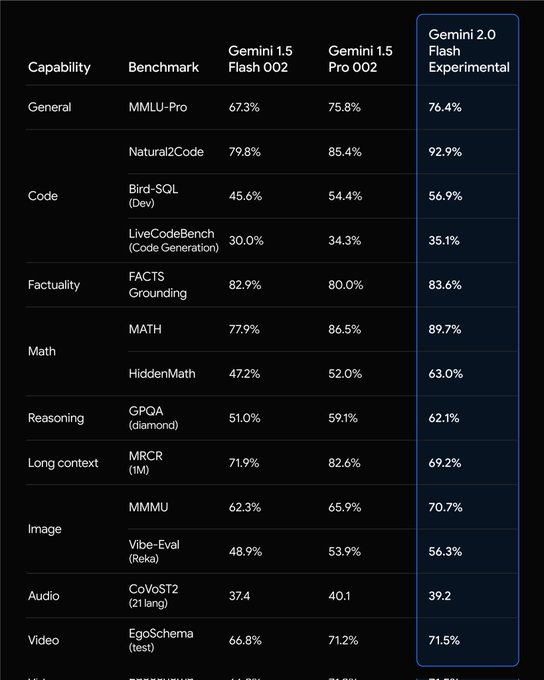
Google DeepMind Presenta Gemini 2.0: El Futuro de los Agentes de IA Multimodales
Google DeepMind ha lanzado Gemini 2.0, una familia de modelos que impulsa una nueva era de "experiencias agénticas". Esta actualización incorpora capacidades multimodales avanzadas, integración de herramientas nativas y una latencia mejorada, marcando un avance significativo hacia asistentes de IA más versátiles y útiles.
Puntos Clave:
Gemini 2.0 Flash: Rápido, Multimodal y Potente
Gemini 2.0 Flash, el modelo principal de esta serie, ofrece soporte para entradas y salidas multimodales como texto, imágenes, video y audio. Además, integra herramientas como Google Search y funciones definidas por el usuario. Con el doble de velocidad que su predecesor, 1.5 Pro, es ideal para desarrolladores a través de la API de Gemini en Google AI Studio y Vertex AI.Nuevos Prototipos Agénticos
Proyectos como Astra, Mariner y Jules exploran aplicaciones prácticas de agentes de IA: desde asistentes universales capaces de recordar conversaciones hasta navegadores que completan tareas complejas y herramientas para desarrolladores que automatizan flujos de trabajo en GitHub. Estas iniciativas muestran cómo los agentes pueden ser útiles en el día a día.Impacto en Juegos y Robótica
Gemini 2.0 también se aplica a entornos virtuales y físicos. En videojuegos, los agentes pueden analizar la acción en pantalla y ofrecer sugerencias en tiempo real. En el mundo físico, las capacidades de razonamiento espacial del modelo se están explorando para aplicaciones robóticas.
Gemini 2.0 establece un estándar en la evolución de agentes de IA multimodales, ampliando sus aplicaciones en áreas como la productividad, el aprendizaje y el entretenimiento. Este enfoque pionero impulsa el avance hacia una IA más accesible, poderosa y ética, marcando un paso crucial hacia el desarrollo de inteligencia general artificial (AGI).
LINK: https://blog.google/technology/google-deepmind/google-gemini-ai-update-december-2024/
Google y Samsung presentan Android XR: El futuro de la IA en gafas inteligentes
Google y Samsung han unido fuerzas para desarrollar Android XR, una nueva plataforma diseñada para dispositivos de realidad extendida (XR), como gafas inteligentes y cascos inmersivos. Este avance, impulsado por el potente modelo de IA Gemini 2.0, promete transformar la interacción entre los usuarios y el mundo digital.
Aunque aún en fase de prototipo, estas gafas inteligentes podrían redefinir cómo interactuamos con la tecnología, consolidando a la inteligencia artificial como parte integral de nuestras rutinas diarias.
Google presenta el procesador cuántico Willow: Un Avance Clave hacia Computadoras Cuánticas Escalables
Google Research ha presentado Willow, el primer procesador cuántico que mejora exponencialmente su rendimiento a medida que aumenta el tamaño de los qubits corregidos por error, marcando un hito en la computación cuántica.
Puntos Clave:
Corrección de Errores por Debajo del Umbral
Willow logra operar “por debajo del umbral”, un objetivo perseguido durante casi tres décadas en computación cuántica. Esto significa que aumentar el tamaño de las cuadrículas de qubits no solo no introduce más errores, sino que mejora exponencialmente el rendimiento. Por ejemplo, un aumento de una cuadrícula 3x3 a una 7x7 redujo las tasas de error por un factor de 2,14, estableciendo un nuevo estándar en corrección de errores.Mejoras en Hardware y Software
Con 105 qubits superconductores, Willow supera al procesador Sycamore en durabilidad (de 20 μs a 68 μs) y aprovecha algoritmos avanzados de aprendizaje automático para identificar y corregir errores. Estas innovaciones permiten que los qubits lógicos superen el rendimiento de los qubits físicos.Preparando el Camino para el Futuro
A pesar de los avances, quedan desafíos clave, como reducir las tasas de error a niveles de una en un trillón y mejorar la velocidad de las operaciones cuánticas corregidas por error. Sin embargo, los avances recientes, incluido un curso gratuito en Coursera sobre corrección de errores, buscan acelerar la adopción y colaboración en este campo.
El desarrollo de Willow marca un paso decisivo hacia la creación de computadoras cuánticas escalables y confiables. Estas máquinas podrían revolucionar campos como la criptografía, la química y la optimización. Aunque los retos técnicos persisten, los avances exponenciales indican que estamos más cerca que nunca de realizar el potencial completo de la computación cuántica.
Microsoft
Copilot Vision: Una Nueva Forma de Navegar en la Web
Microsoft ha anunciado el lanzamiento en vista previa de Copilot Vision, una funcionalidad integrada en Microsoft Edge que utiliza inteligencia artificial para transformar la experiencia de navegación. Este avance permite a los usuarios interactuar con la web de manera más contextual y personalizada.
Puntos Clave:
Navegación Inteligente y Contextual
Copilot Vision, disponible exclusivamente en Microsoft Edge, puede analizar y entender el contenido de las páginas web que visitas, ayudándote con tareas como planificar actividades, realizar compras más informadas o aprender nuevas habilidades. Todo esto se realiza en tiempo real, brindando sugerencias y perspectivas útiles mientras navegas.Privacidad y Control del Usuario
La funcionalidad es completamente opcional y respeta la privacidad del usuario. Los datos compartidos durante las sesiones no se almacenan, y solo las respuestas de Copilot se registran para mejorar la seguridad. Además, Vision opera dentro de un marco estricto que prioriza la protección de derechos de autor y la seguridad del usuario.Lanzamiento Controlado y Feedback Activo
Actualmente, Copilot Vision está disponible para un grupo limitado de suscriptores de Copilot Pro en EE. UU., interactuando únicamente con sitios web seleccionados. Microsoft recopila comentarios de testers externos y editores para perfeccionar la experiencia antes de expandir su disponibilidad.
Copilot Vision marca un avance significativo en el uso de la IA para una navegación más intuitiva y eficiente. Al combinar tecnología avanzada con un enfoque en privacidad, esta herramienta puede redefinir cómo interactuamos con la web, haciéndola más accesible y personalizada. Sin embargo, su implementación gradual refleja el compromiso de Microsoft con la seguridad y la transparencia en el desarrollo de tecnologías de IA.
Phi-4: Un Modelo de 14B Parámetros que Revoluciona el Razonamiento Matemático
Microsoft ha presentado Phi-4, un modelo de lenguaje con 14.000 millones de parámetros que iguala el rendimiento de sistemas mucho más grandes como GPT-4o-mini y Llama-3.3-70B en tareas complejas de razonamiento, logrando un 91.8% de precisión en problemas matemáticos del nivel AMC 10/12. Sin embargo, su uso está limitado por una licencia no comercial.
Puntos Clave:
Rendimiento Excepcional en Razonamiento Matemático
Phi-4 supera a modelos más grandes como Gemini Pro 1.5 y Llama-3.3-70B en precisión matemática, logrando un 91.8% en problemas de competencia como AMC 10/12. Su tamaño compacto demuestra que los modelos pequeños pueden rivalizar con los grandes cuando se optimizan adecuadamente.Innovaciones Técnicas Clave
El modelo se basa en innovaciones como generación sintética avanzada de datos, curación de datos orgánicos de alta calidad y métodos post-entrenamiento innovadores como Pivotal Token Search (PTS). PTS acelera la inferencia 3 veces, reduce el uso de memoria entre un 40-60% y mantiene más del 95% de precisión al enfocarse en los tokens más relevantes durante el procesamiento.Disponibilidad Limitada y Potencial
Actualmente, Phi-4 está disponible bajo una licencia de investigación en Azure AI Foundry y pronto en Hugging Face. Sin embargo, su uso limitado por una licencia no comercial restringe su impacto inmediato en aplicaciones comerciales.
Phi-4 destaca el potencial de modelos pequeños para igualar o superar a los grandes, lo que podría reducir significativamente los costos computacionales en el futuro. Este avance no solo desafía la tendencia hacia modelos masivos, sino que también aborda problemas clave de escalabilidad. Sin embargo, la falta de una licencia comercial limita su adopción inmediata más allá del ámbito académico.
Aurora: Nuevo Modelo de Generación de Imágenes en Grok, que ahora está disponible para todos los usuarios
La plataforma 𝕏 incorpora Aurora, un modelo autoregresivo de generación de imágenes que combina texto e imagen para crear contenido visual de alta calidad, desde retratos fotorrealistas hasta arte conceptual.
Puntos Clave:
Modelo Autoregresivo y Multimodal
Aurora está diseñado para predecir el próximo token a partir de datos intercalados de texto e imagen, permitiendo una comprensión profunda del contexto. Puede generar imágenes fotorrealistas a partir de descripciones textuales y editar imágenes proporcionadas por el usuario, otorgando un control creativo sin precedentes.Capacidades Avanzadas de Generación y Edición
Este modelo sobresale en tareas desafiantes como el diseño de logotipos, la creación de retratos realistas y la representación de conceptos abstractos. Además, incluye soporte para edición de imágenes, lo que permite transformar imágenes existentes en tiempo real, una funcionalidad que llegará pronto a todos los usuarios.Disponibilidad Progresiva
Las nuevas capacidades de Grok ya están activas en países seleccionados a través de la plataforma 𝕏, y se espera un despliegue global en una semana, ampliando el acceso a estas herramientas revolucionarias.
El lanzamiento de Aurora posiciona a Grok como líder en generación de imágenes multimodales, revolucionando industrias como el diseño, la publicidad y la creatividad digital. Al cerrar la brecha entre texto e imagen, esta tecnología redefine cómo interactuamos con modelos generativos, ofreciendo mayor precisión, control y versatilidad.