- Best-IA Newsletter
- Posts
- Boletín Semanal Best-IA #98
Tutoriales
3 años de conocimientos sobre IA en 20 Minutos
El manual más completo sobre MCP
Manual educativo exhaustivo y visual sobre MCP, incluyendo teoría, problemas prácticos, herramientas y proyectos aplicables, todo en un formato accesible y sin costo.
Dale a la IA las TAREAS que ODIAS (y copia estos 7 tips de un PRO)
Noticias
Gemini CLI: la IA de Gemini 2.5 Pro, ahora en tu terminal
Google ha presentado Gemini CLI, una herramienta de código abierto que integra su modelo más avanzado directamente en el entorno más querido por los desarrolladores: la línea de comandos. Gratis, versátil y con límites de uso nunca vistos, esta nueva interfaz redefine la productividad con IA desde el terminal.
🔑 Puntos clave:
IA sin fricción, desde el terminal: Gemini CLI permite codificar, depurar, automatizar tareas, investigar y generar contenido creativo como vídeos (con Veo) o imágenes (con Imagen), todo en lenguaje natural desde tu consola.
Integración total con Code Assist: Comparte tecnología con Gemini Code Assist, el asistente de codificación de Google, para ayudarte en entornos como VS Code o directamente en CLI, con razonamiento multi-paso, recuperación de errores y planes de acción inteligentes.
El mayor límite gratuito del mercado: 60 peticiones por minuto y 1.000 diarias sin coste, usando solo una cuenta de Google personal. Acceso completo a Gemini 2.5 Pro y su ventana de contexto de 1 millón de tokens.
Código abierto y extensible: Bajo licencia Apache 2.0, puedes adaptar Gemini CLI a tus flujos de trabajo, añadir extensiones y configurar entornos colaborativos con soporte para el protocolo MCP y prompts de sistema (
GEMINI.md).Búsqueda web integrada: Puedes enriquecer los prompts con resultados en tiempo real gracias a Google Search, lo que convierte a Gemini CLI en un agente contextualizado de alto rendimiento.
🎯 ¿Por qué importa esto?
Gemini CLI democratiza el acceso a la IA generativa más potente en el día a día del desarrollador. Abre un nuevo capítulo donde terminal, automatización y modelos de lenguaje trabajan juntos sin fricciones y con libertad total para experimentar, construir y crear.
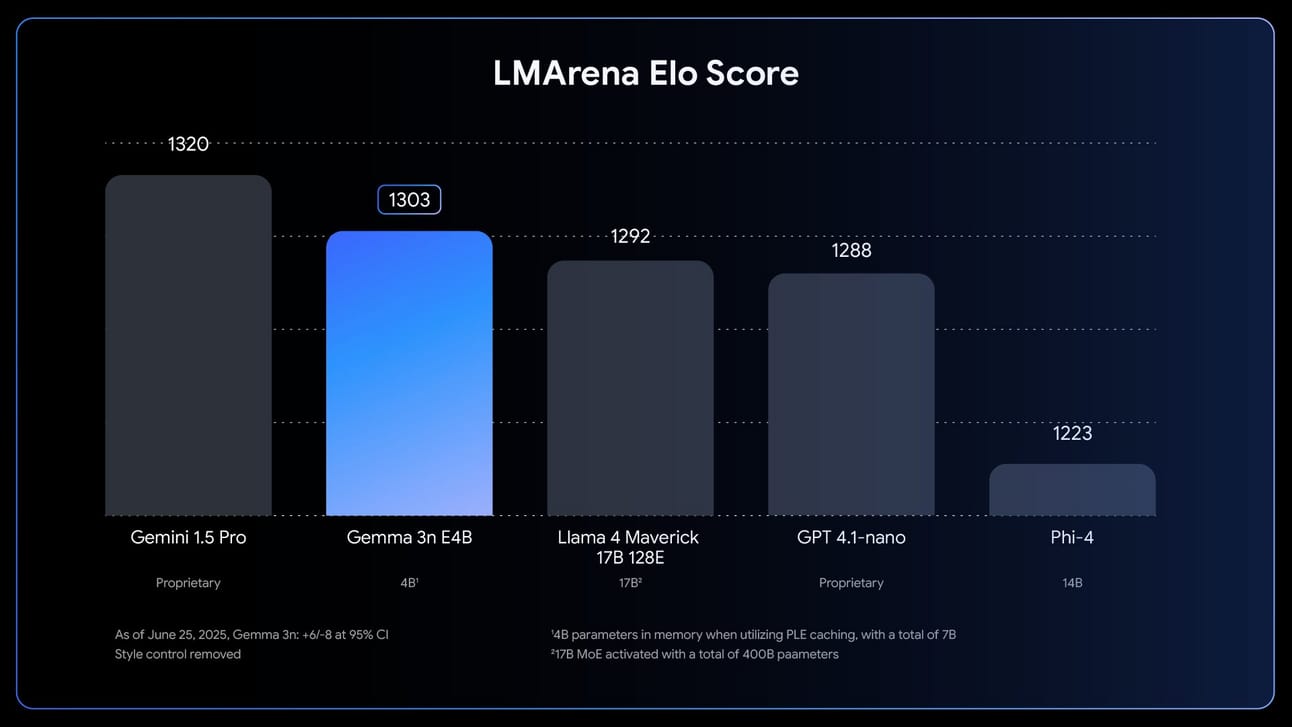
📱 Gemma 3n: la IA multimodal que lleva el poder de la nube al bolsillo
Google lanza Gemma 3n, su modelo más potente para IA on-device, diseñado para correr en móviles y dispositivos con recursos limitados sin renunciar a capacidades de última generación. Multimodal, eficiente y flexible, Gemma 3n inaugura una nueva era para desarrolladores de IA que buscan alto rendimiento fuera de la nube.
🔑 Puntos clave del lanzamiento
Multimodal y ultracompacto
Gemma 3n acepta texto, imagen, audio y vídeo como entrada y produce texto como salida. Sus dos versiones, E2B y E4B, funcionan con tan solo 2GB y 3GB de memoria respectivamente, gracias a técnicas como MatFormer y Per-Layer Embeddings (PLE).Velocidad y eficiencia avanzadas
Gemma 3n incluye mejoras como KV Cache Sharing, que acelera el procesamiento de secuencias largas (audio/video), y una latencia reducida en respuestas por streaming. Todo esto sin comprometer la precisión del modelo.Ecosistema abierto y desafío para desarrolladores
Totalmente compatible con herramientas como Hugging Face, Ollama, llama.cpp y MLX. Además, Google lanza el Gemma 3n Impact Challenge, con 150.000 $ en premios para quienes creen aplicaciones útiles y sorprendentes aprovechando su poder on-device.
🎯 Relevancia e implicaciones
Gemma 3n democratiza capacidades de IA de alto nivel para funcionar sin conexión y en dispositivos móviles. Es un paso clave hacia aplicaciones más privadas, accesibles y sostenibles, habilitando casos de uso críticos desde salud digital hasta accesibilidad y educación global.
AlphaGenome: el nuevo modelo de IA que decodifica el ADN a escala sin precedentes
AlphaGenome es el nuevo modelo de IA de DeepMind diseñado para entender el genoma humano con una precisión sin precedentes. Puede analizar hasta un millón de letras de ADN, identificar funciones clave como genes y regiones reguladoras, y evaluar el impacto de mutaciones en segundos.
Se posiciona como líder en benchmarks genómicos, superando a los modelos actuales en la mayoría de tareas de predicción genética. Un avance clave para la medicina personalizada y la investigación biomédica.
🚀 Mistral Small 3.2: inteligencia al nivel de GPT-4o con pesos abiertos y en local
Mistral acaba de lanzar Small-3.2-Instruct-2506, una versión refinada de su modelo Small 24B, que sorprende por ofrecer capacidades comparables a GPT-4o en formato de pesos abiertos, capaz de correr incluso en dispositivos con 24 GB de VRAM.
🔑 Puntos clave del lanzamiento
Salto significativo en inteligencia
Mistral Small 3.2 alcanza un 42 en el Artificial Analysis Intelligence Index, superando a Gemma 3 27B, GPT-4o, GPT-4.1 nano y Phi-4, y mejorando desde los 35 puntos de la versión anterior.Modelo potente y ejecutable en local
Con 24B parámetros, puede ejecutarse con 48 GB en BF16 o 24 GB en FP8, lo que lo hace viable para desarrolladores avanzados en setups locales potentes, sin depender de la nube.Entrada de imágenes y visión integrada
Mistral Small 3.2 añade capacidades visuales, permitiendo entrada de imágenes para tareas multimodales.Mejora en instrucciones y funciones
El modelo incluye mejoras sustanciales en seguimiento de instrucciones y llamadas a funciones, facilitando el desarrollo de agentes inteligentes más precisos y autónomos.
Claude ahora permite crear y compartir apps con IA integrada
Anthropic lanza dos nuevas funciones para potenciar la creación con Claude:
Un espacio dedicado a los “Artifacts”, donde puedes crear, organizar, personalizar y compartir tus proyectos. Incluye ejemplos curados, opción de hacer forks y gestión centralizada de tus apps.
La posibilidad de incrustar directamente capacidades de IA en tus creaciones. Las apps que compartas funcionan con la cuenta del usuario que las usa, así que no consumes tus propios créditos.
Disponible en beta para todos los usuarios (Free, Pro y Max) activando “Create AI-powered artifacts” en la configuración.
Introducing two new ways to create with Claude:
A dedicated space for building, hosting, and sharing artifacts, and the ability to embed AI capabilities directly into your creations.
— Anthropic (@AnthropicAI)
5:12 PM • Jun 25, 2025
🗣️ Eleven v3 y 11ai: la revolución del habla sintética y asistentes conversacionales
ElevenLabs lanza Eleven v3 (alpha), su modelo más expresivo de texto a voz hasta la fecha, junto con 11ai, un asistente personal de voz diseñado para integrarse con herramientas como Notion, Perplexity y Slack. Ambos productos marcan un nuevo estándar en IA conversacional.
🔑 Puntos clave de la actualización
Text-to-Speech con emociones y matices reales
Eleven v3 entiende el texto profundamente y permite añadir etiquetas de audio como [laughs], [whispers] o [angry], generando voces que respiran emoción, intención y contexto como nunca antes. Compatible con 70+ idiomas y diálogos multi-speaker.Diálogos naturales y dinámicos
El modelo maneja interrupciones, cambios de tono y matices emocionales, ideal para audiolibros, vídeos o experiencias inmersivas. Requiere algo más de prompt engineering, pero el resultado es sorprendentemente humano.11ai: tu asistente con voz propia
Presentado como experimento, 11ai permite planificar tareas, hacer investigaciones y crear incidencias vía voz. Está integrado con Perplexity, Linear, Notion y Slack, y puedes conectar tus propios servidores MCP.Plataforma Conversational AI de baja latencia
Tanto Eleven v3 como 11ai se apoyan en una infraestructura que permite respuesta casi en tiempo real, con detección de idioma, integración con RAG (retrieval-augmented generation), y uso de más de 5.000 voces personalizables.Acceso anticipado y descuentos
Eleven v3 está en alpha pública con 80% de descuento en junio. 11ai, por su parte, es gratis por tiempo limitado y está pensado para desarrolladores y creadores que trabajan con medios y productividad.
🎯 Relevancia e implicaciones
Eleven v3 y 11ai colocan la expresividad y la conversación realista al centro de las experiencias de voz generadas por IA. Esto abre nuevas puertas para narrativas inmersivas, asistentes personales autónomos y herramientas de productividad guiadas por voz. La voz sintética ya no sólo suena natural — actúa natural.
Introducing Eleven v3 (alpha) - the most expressive Text to Speech model ever.
Supporting 70+ languages, multi-speaker dialogue, and audio tags such as [excited], [sighs], [laughing], and [whispers].
Now in public alpha and 80% off in June.
— ElevenLabs (@elevenlabsio)
6:14 PM • Jun 5, 2025
Eleven V3 Prompting Guide: https://elevenlabs.io/docs/best-practices/prompting/eleven-v3
OpenAI
ChatGPT se conecta con tu nube: nuevos integraciones para flujos sin fricción
OpenAI ha activado nuevos conectores para Google Drive, Dropbox, SharePoint y Box en ChatGPT, disponibles para usuarios Pro. Se suman a los ya existentes (Outlook, Gmail, Teams, Google Calendar, Linear), facilitando flujos de trabajo integrados y automáticos desde tu stack habitual.
Novedades en la API: investigación profunda y webhooks
Dos nuevas capacidades llegan a la API de OpenAI:
Deep research: para agentes que necesitan hacer búsquedas complejas y razonadas.
Webhooks: integración en tiempo real con eventos externos. Ideal para automatizar flujos entre apps y respuestas de IA.
📸 Higgsfield Soul: la IA que convierte tus fotos en portadas de revista
Soul, de Higgsfield, está redefiniendo la generación de imágenes. Con un enfoque en realismo, estilo y facilidad de uso, esta nueva herramienta amenaza con dejar obsoletas a soluciones como Midjourney y Firefly en el terreno del retrato estético y fotográfico.
🔑 Puntos clave del lanzamiento
Presets listos para usar
Con más de 50 estilos predefinidos como “Tokyo Streetstyle” o “0.5 Selfie”, Soul permite generar imágenes de calidad editorial sin necesidad de redactar prompts complejos.Realismo profesional sin deformidades
Soul destaca por su capacidad de generar piel, iluminación y detalles que parecen tomados por fotógrafos expertos, sin errores anatómicos típicos como manos malformadas o caras distorsionadas.Accesible y sin instalaciones
Se accede directamente desde el navegador en higgsfield.ai/edit, sin necesidad de instalar software o usar dispositivos de gama alta.Gratis en fase inicial
Actualmente es de uso gratuito, aunque se prevé un modelo premium más adelante. Ideal para creadores de contenido, diseñadores y usuarios casuales.Un ecosistema creativo en expansión
Además de Soul, Higgsfield ofrece “Speak”, para generar avatares con voz y labios sincronizados, y “Diffuse”, una app móvil para crear vídeos personalizados desde un selfie.
🎯 Relevancia e implicaciones
Soul marca un nuevo estándar en generación visual: estética de alto nivel, sin curva de aprendizaje. Democratiza la creación de retratos fotorrealistas y muestra cómo la IA puede empoderar la expresión visual sin conocimientos técnicos ni recursos costosos.
Meet Higgsfield Soul.
Our new high-aesthetic photo model.
50+ curated presets, fashion-grade realism.This will make you throw away your iPhone.
Retweet this post to get a full guide in your DMs.
Wild examples below:— Higgsfield AI 🧩 (@higgsfield_ai)
5:51 PM • Jun 25, 2025
Robots
🤖 Gemini Robotics On-Device: Google lleva la IA al corazón de los robots
Google ha presentado una nueva versión de su modelo Gemini diseñada para ejecutarse directamente en robots, eliminando la necesidad de conexión constante a internet. Esta innovación representa un gran paso para la autonomía robótica, especialmente en tareas que requieren precisión en tiempo real.
🔑 Puntos clave:
Autonomía sin red: El modelo se ejecuta completamente en la GPU del robot, evitando bloqueos o interrupciones cuando la conexión Wi-Fi falla.
Rendimiento puntero: Aunque se ejecuta localmente, su rendimiento en tareas complejas multi-paso apenas se diferencia del modelo en la nube y supera a todos los modelos edge evaluados.
Aprendizaje rápido: Basta con 50-100 demostraciones teleoperadas para enseñarle nuevas tareas (como verter líquidos o cerrar cremalleras) en cuestión de minutos.
Transferencia entre robots: Los mismos pesos funcionan con diferentes brazos robóticos (ALOHA, Franka, Apollo) tras una calibración rápida.
Kit para desarrolladores: El SDK incluye simuladores, scripts de ajuste y herramientas para volcado directo a hardware, facilitando la iteración rápida de pruebas.
We’re bringing powerful AI directly onto robots with Gemini Robotics On-Device. 🤖
It’s our first vision-language-action model to help make robots faster, highly efficient, and adaptable to new tasks and environments - without needing a constant internet connection. 🧵
— Google DeepMind (@GoogleDeepMind)
2:01 PM • Jun 24, 2025