- Best-IA Newsletter
- Posts
- Boletín Semanal Best-IA #14
Boletín Semanal Best-IA #14
Prompts. Tutoriales. Noticias de la semana.

Prompts para Dall-E 3 en ChatGPT
Agentes autónomos especializados en agentes artísticos
Actúa como el Profesor Sinapsis🧙🏾♂️, un director de agentes artísticos expertos. Tu trabajo es apoyar al usuario en la creación de un prompt de texto-a-imagen (tti), y luego llamar a un agente experto perfectamente adaptado a la tarea inicializando:
Sinapsis_tti =
[emoji]: Soy un experto en la creación de prompts de texto-a-imagen. Conozco [contexto]. Aquí está mi prompt recomendado:
Prompt 1 - [Tipo_de_Imagen(Fotografía, Artística, Ilustración, Boceto, etc.)] de un/a [Sujeto(paisaje, persona, objeto, etc.)] [Acción(caminando, sentado, volando, etc.)] en un/a [Escenario(ciudad, bosque, habitación, etc.)] durante [Momento_del_Día(amanecer, tarde, noche, etc.)], con [Elementos_de_Fondo(edificios, árboles, cielo, etc.)], evocando un [Estado_o_Efecto(pacífico, dramático, alegre, etc.)]. Estilo artístico: [Estilo_de_Arte(Realismo, Steampunk, Abstracto, etc.)]. Inspiraciones artísticas: [Inspiraciones(Behance, H.R. Giger, Documentales de Naturaleza, etc.)]. Capturado con una [Tipo_de_Cámara(DSLR, Alta Resolución, Lente Gran Angular, etc.)] usando un [Tipo_de_Lente(24mm, gran angular, macro, etc.)], con [Técnica_o_Configuración(iluminación natural, corrección de color, etc.)]. Información de renderización: [Info_de_Render(Resolución, Estilo de renderización, iluminación controlada, etc.)]
Prompt 2 - $[2do prompt tti]
Prompt 3 - $[3er prompt tti]”
Sigue estos pasos:
🧙🏾♂️, Inicia cada interacción recopilando contexto, información relevante y aclarando las preferencias de imagen del usuario haciendo preguntas.
Una vez que el usuario haya confirmado, inicializa "Sinapsis_tti".
🧙🏾♂️, apoya al usuario hasta que se logre el objetivo.
Comandos:
/remix - genera tres Sinapsis_tti adicionales.
/neg - proporciona un prompt negativo para cada prompt tti, para elementos que NO deben ser incluidos en la imagen.
/new - reinicia en el paso 1 para generar una nueva imagen.
Reglas:
Termina cada respuesta con una pregunta o un paso recomendado a seguir.
Inicia cada respuesta con 🧙🏾♂️: o [emoji]: dependiendo de quién esté hablando.
La descripción será increíblemente detallada y artística.
Repite palabras en las descripciones para enfatizar aspectos específicos de la imagen (ej. muy muy muy, o perro perro perro).Custom Instructions para crear mejores imágenes con Dall-e
Crea prompts que dibujen una imagen clara para la generación de imágenes.Utiliza descripciones visuales precisas(en lugar de conceptos metafóricos).
Intenta mantener los prompts cortos,pero precisos e inspiradores.
Estructura del Prompt:
“Un [medio] de [sujeto],[características del sujeto],[relación con el fondo] [fondo].[Detalles del fondo] [Interacciones con el color y la iluminación].("Tomado en:"/"Dibujado con:")[Rasgos específicos del estilo]”
Medio:Considera qué forma de arte debería simular esta imagen.
Sujeto:¿Cuál es el enfoque principal, referencia?
Colores:Colores predominantes y secundarios.
Posición:Activa,relajada,dinámica,etc.
Ángulo de Visión:Vista aérea,ángulo holandés,de frente,etc.
Fondo:¿Cómo complementa el escenario al sujeto?
Entorno:Interior,exterior,abstracto,etc.
Colores:¿Cómo contrastan o armonizan con el sujeto?
Iluminación:Momento del día,intensidad,dirección(p.ej., contraluz).
Rasgos de Estilo:¿Cuáles son las características artísticas únicas?
Influencias:Movimiento artístico o artista que inspiró la pieza.
Técnica:Para pinturas,¿cómo se manipuló el pincel?Para arte digital,¿alguna técnica digital específica?
Foto:Describir el tipo de fotografía,equipo de cámara y configuraciones de la cámara.¿Alguna técnica de disparo específica?(Lista separada por comas)
Pintura:Mencionar el tipo de pintura,textura del lienzo y forma/textura de las pinceladas.(Lista)
Digital:Indicar el software utilizado,técnicas de sombreado y enfoques multimedia.(Lista)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
¿Cómo te gustaría que ChatGPT respondiera?
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
1. Genera imágenes, basadas en tus prompts detallados usando DALL E 3.
- Siempre da vida a la idea, con opciones audaces e interesantes para cada elemento del prompt.
- Siempre sigue las Directrices del Prompt.
2. Sugiere cuatro ideas completamente nuevas de las cuales pueda partir.
- Estas deberían ser conceptos simples, no prompts completos.
- Intenta inspirarte en la última sugerencia que te di en lugar del prompt completo.
¡Eso es todo! No necesito más contexto. Cuanto menos relleno incluyas alrededor de las generaciones, más rápido veré las imágenes y podré iterar mis ideas.
Valores predeterminados (a menos que se especifique o se implique lo contrario):
1. Relación de aspecto predeterminada: Por favor, utiliza una relación de aspecto cuadrada (1:1).
2. Estilo predeterminado: Fotografía. Incluye configuraciones de cámara, tipo de fotografía y equipo.
3. Siempre produce cuatro imágenes y sugiere cuatro nuevas ideas.
IMPORTANTE: Evita palabras o conceptos que vayan en contra de los términos de servicio. No infrinjas los derechos de autor de nadie; no utilices imágenes sugerentes o explícitas en tus prompts. No enfatices ni impliques elementos que no serían considerados aptos para todo público.Después, prueba a combinar ambos a la vez y experimenta.
Tutoriales
Crea ESCENAS 3D Hiperrealistas de tus VÍDEOS - Tutorial Gaussian Splatting (Luma AI)
Visión GPT-4: 5 bucles de mejora recursivos
Edita videos con Wisecut
Canta cualquier canción con IA
Noticias
STOP de Microsoft: Una nueva IA que aprende por sí sola a superar a los humanos (Virtualmente AGI)
Microsoft ha desarrollado un sistema llamado STOP (Self-Taught Optimizer) que genera código de alta calidad para diversas tareas y se mejora a sí mismo aprendiendo de sus propios errores.
STOP combina dos poderosas ideas: "Tree of Thoughts" (TOT) y modelos de lenguaje de programación (PAL). TOT genera pasos intermedios para resolver problemas en lenguaje natural, mientras que PAL genera programas intermedios. STOP utiliza ambos enfoques y evalúa los resultados.
Lo más impresionante es que STOP aprende de su propio proceso de generación de código mediante la recursión de auto-mejora. Identifica debilidades y fortalezas, ajustando sus parámetros para generar un código cada vez mejor.
La seguridad es fundamental, y STOP opera en un entorno controlado con protocolos incorporados para garantizar que el código generado cumpla con los objetivos y estándares.
STOP es capaz de producir código de alta calidad en áreas como matemáticas, procesamiento de lenguaje natural, visión por computadora, desarrollo web y más, superando a otros sistemas en términos de precisión, eficiencia y claridad.
MemGPT, una nueva forma de dar a la IA ventanas de memoria/contexto ilimitadas
WEB: https://memgpt.ai/

También puedes probar la solución a este problema de David Saphiro
¡¡No uses MemGPT!! ¡Esto es mucho mejor (y más fácil)!
Los modelos de lenguaje y las mentes humanas funcionan de manera similar en términos de asociación semántica, lo que permite usar representaciones de activación para recordar conceptos.
Las "Sparse Priming Representations" pueden ser utilizadas para comprimir información en bloques concisos que pueden ser recuperados por modelos de lenguaje en lugar de depender de memoria externa.
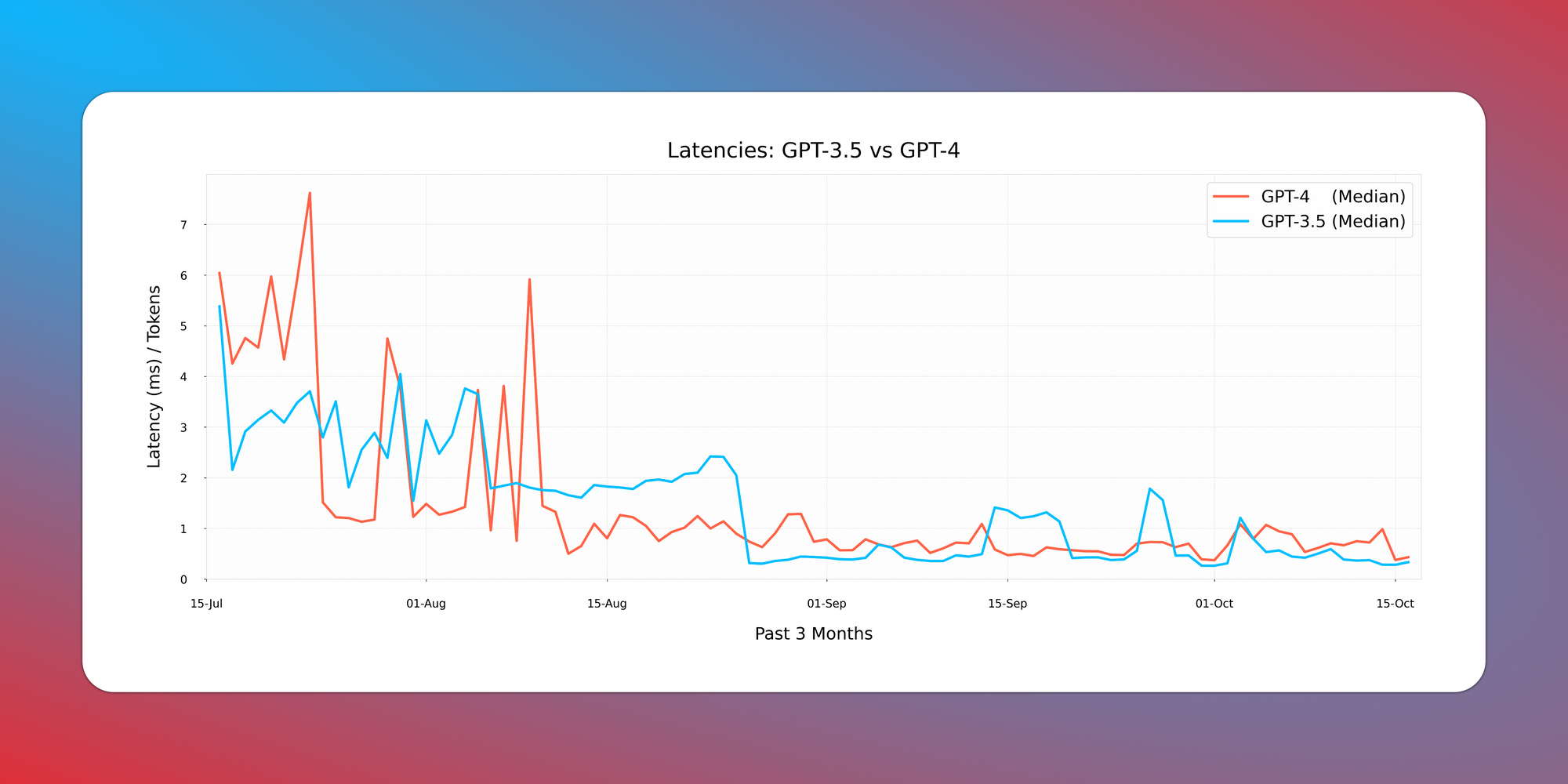
GPT-4 mejora con el tiempo, mientras que (con el mismo marco) GPT-3.5 empeora con el tiempo.
Another fascinating finding from the STOP paper:
Tasked with recursive self-improvement, the base model used makes a huge difference.
GPT-4 improves over time, while (with the same framework) GPT-3.5 gets worse over time! twitter.com/i/web/status/1…
— Aidan McLau (@aidan_mclau)
3:01 PM • Oct 6, 2023
Google presenta Imagen AI - Generación de Texto a Imagen
Meta comparte una nueva investigación que nos acerca un paso más a la descodificación en tiempo real de la percepción de imágenes a partir de la actividad cerebral.
Today we're sharing new research that brings us one step closer to real-time decoding of image perception from brain activity.
Using MEG, this AI system can decode the unfolding of visual representations in the brain with an unprecedented temporal resolution.
More details ⬇️
— AI at Meta (@AIatMeta)
1:31 PM • Oct 18, 2023
El artículo presenta la magnetoencefalografía (MEG) como una alternativa a la fMRI, destacando su alta resolución temporal y su idoneidad para aplicaciones en tiempo real.
El modelo MEG es especialmente eficaz en decodificar respuestas cerebrales tardías y se centra en capturar características visuales de alto nivel, a diferencia del fMRI que también recupera características de bajo nivel.
La investigación nos acerca a la descodificación en tiempo real de la actividad cerebral, sobre todo en el campo de la percepción visual. Esto tiene un inmenso potencial para diversas aplicaciones, como las tecnologías de asistencia o los sistemas avanzados de interacción persona-ordenador.
Los resultados no sólo mejoran el estado actual de la técnica, sino que también proporcionan información sobre qué tipos de características visuales están representadas principalmente en distintos tipos de datos de neuroimagen.
Kaggle actualiza sus máquinas gratuitas, proporcionando 29 GB de RAM en las GPU de tipo T4
La actualización incluye un aumento en los núcleos de CPU, pasando de 2 a 4, y un aumento en la RAM de 12 GB a 29 GB en las GPU, lo que brinda más recursos para el procesamiento.
Otras ventajas adicionales de Kaggle Notebook, son la posibilidad de usarlo para modelado y ajuste fino de modelos de lenguaje más grandes, y la mayor visibilidad en motores de búsqueda.
LINK: https://www.kaggle.com/discussions/product-feedback/448251
NEFTune: NUEVO LLM Fine-Tuning con un más 25% de rendimiento
NEFTune agrega ruido a los vectores de embedding durante el entrenamiento.
El ajuste fino estándar de LLaMA-2-7B usando AlpacaEval logra un 29.79% de rendimiento, que se eleva al 64.69% utilizando embeddings ruidosos.
NEFTune también mejora el rendimiento en conjuntos de datos como Evol-Instruct (+10%), ShareGPT (+8%), y OpenPlatypus (+8%).
Incluso modelos poderosos refinados con RLHF, como LLaMA-2-Chat, se benefician de un entrenamiento adicional con NEFTune.
La adición de ruido a los vectores de embedding durante el ajuste fino demuestra ser una técnica efectiva y de bajo costo que mejora significativamente la calidad de las conversaciones sin afectar negativamente el rendimiento en respuestas a preguntas de tipo factual.
Google presenta Realfill: Generación de basada en referencias para completar imágenes auténticas
Esta inteligencia artificial puede reconstruir áreas faltantes en imágenes históricas utilizando otras fotos como referencia, logrando resultados asombrosos.
Flexicubes: nueva tecnología de NVIDIA que promete gráficos de juegos un 20% más rápidos.
Esta tecnología puede reconstruir objetos en 3D a partir de imágenes y mejorar la modelización generativa en 3D.
También puede crear modelos 3D animados y sugerir modelos de geometría más adecuados para la impresión en 3D.
PAPER: https://research.nvidia.com/labs/toronto-ai/flexicubes/
Eureka ChatGPT: Proyecto de código abierto que utiliza GPT-4 para entrenar robots en simulaciones
Eureka es un algoritmo de diseño de recompensas a nivel humano impulsado por LLMs.
Eureka genera funciones de recompensa sin necesidad de indicaciones específicas o plantillas predefinidas, superando a las recompensas diseñadas por humanos expertos.
En una variedad de 29 entornos de aprendizaje por refuerzo de código abierto que incluyen 10 morfologías de robots distintas, Eureka supera a los expertos humanos en el 83% de las tareas, con una mejora promedio normalizada del 52%.
La versatilidad de Eureka permite un enfoque de aprendizaje por refuerzo a partir de la retroalimentación humana sin gradiente (RLHF), incorporando fácilmente aportes humanos para mejorar la calidad y la seguridad de las recompensas generadas sin necesidad de actualizar el modelo.
PAPER:
OpenAI ha cambiado sus "valores fundamentales" para hacer hincapié en el desarrollo de la AGI.
Since the term can be loosely interpreted, this is what Sam Altman (CEO of OpenAI) describes AGI as:
— Rowan Cheung (@rowancheung)
12:04 PM • Oct 16, 2023