- Best-IA Newsletter
- Posts
- Boletín Semanal Best-IA #48
Tutoriales
Praison AI: Creación automática de agentes de IA para automatización de trabajos
DOCUMENTACIÓN: https://docs.praison.ai/
Noticias
Anthropic lanza Claude 3.5 Sonnet, su modelo más inteligente que aspira a superar a GPT-4o
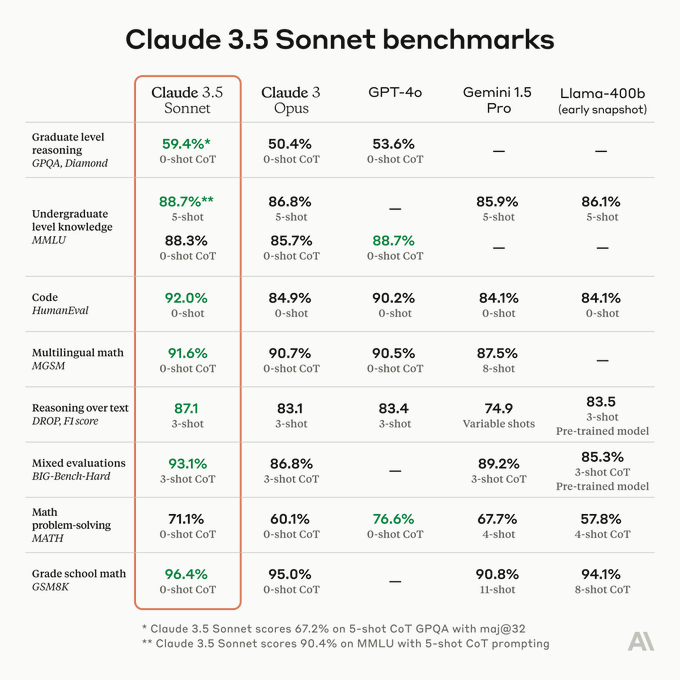
Claude 3.5 Sonnet es el primer modelo de la nueva familia Claude 3.5, superando a sus predecesores y competidores en evaluaciones clave y manteniendo la eficiencia de costo y velocidad. Disponible gratuitamente en Claude.ai y en la app de iOS, también se puede acceder a través de API de Anthropic, Amazon Bedrock, y Google Cloud’s Vertex AI.
Rendimiento Superior: Claude 3.5 Sonnet duplica la velocidad de Claude 3 Opus, destacándose en razonamiento a nivel de posgrado, conocimiento de pregrado y competencia en codificación, con una mejora notable en la comprensión de matices, humor e instrucciones complejas.
Evaluaciones de Codificación y Visión: En evaluaciones internas, resolvió el 64% de los problemas de codificación frente al 38% de Claude 3 Opus, demostrando habilidades avanzadas para escribir, editar y ejecutar código. En tareas de visión, supera a Claude 3 Opus en benchmarks estándar, interpretando gráficos y transcribiendo texto de imágenes imperfectas con alta precisión.
Nuevas Funcionalidades: La introducción de Artifacts en Claude.ai permite a los usuarios generar y editar contenido en tiempo real, mejorando la colaboración y la integración de proyectos. Este avance es el inicio de un entorno de trabajo colaborativo que se expandirá para soportar equipos y organizaciones completas.
It is pretty thrilling to use a tool that is this fast and responsive and willing to roll with it:
"Claude 3.5, build me a game as an workable prototype that teaches about opportunity cost, but is an arcade game with lovecraftian elements"
"Make it better" etc.
All realtime.
— Ethan Mollick (@emollick)
7:10 PM • Jun 20, 2024
Pruébalo en https://claude.ai/
Ilya Sutskever funda su nueva compañía, SSI Inc., para desarrollar superinteligencia segura
Safe Superintelligence Inc. (SSI Inc.) se ha establecido con un único objetivo: desarrollar una superinteligencia segura. Consideran que esta tarea es el desafío técnico más crucial de nuestro tiempo.
Puntos clave:
Misión y Enfoque Exclusivo:
SSI Inc. se dedicará exclusivamente a crear una superinteligencia segura. La empresa, sus inversores y su modelo de negocio están alineados para lograr este objetivo, evitando distracciones y presiones comerciales a corto plazo.Seguridad y Capacidades en Paralelo:
SSI Inc. aborda simultáneamente la seguridad y las capacidades de la superinteligencia. Su estrategia implica avanzar rápidamente en capacidades tecnológicas mientras garantizan que la seguridad siempre esté un paso adelante, asegurando un crecimiento seguro y controlado.Equipo y Localización:
Con oficinas en Palo Alto y Tel Aviv, SSI Inc. aprovecha su presencia en estos hubs tecnológicos para reclutar a los mejores ingenieros e investigadores del mundo. Su equipo está compuesto por expertos dedicados exclusivamente a la misión de SSI.
I am starting a new company:
— Ilya Sutskever (@ilyasut)
5:00 PM • Jun 19, 2024
LINK: https://ssi.inc/
Microsoft lanza Florence-2, un modelo fundacional de visión de 200M y 800M parámetros, líder en el estado del arte
Florence-2 es un modelo fundacional de visión diseñado para realizar una variedad de tareas de visión por computadora y visión-lenguaje usando una representación unificada basada en instrucciones de texto.
Este modelo busca superar las limitaciones de los modelos de visión existentes que, aunque son buenos en aprendizaje por transferencia, tienen dificultades para manejar la diversidad de tareas con instrucciones simples.
El checkpoint de 200M supera a Flamingo 80B (un modelo 400 veces más grande) con una gran ventaja.
Realiza tareas como subtítulos, detección y segmentación de objetos, reconocimiento óptico de caracteres, localización de frases y más.
Aprendizaje multi-tarea: Florence-2 puede aprender y realizar varias tareas de visión al mismo tiempo, lo que le permite comprender mejor la complejidad de la información visual.
Disponible bajo licencia MIT .
Checkpoints en HUGGIN FACE: https://huggingface.co/collections/microsoft/florence-6669f44df0d87d9c3bfb76de
Runway anuncia su nuevo modelo de generación de texto a vídeo: Gen-3 Alpha
Gen-3 Alpha es el primero de una próxima serie de modelos entrenados por Runway en una nueva infraestructura creada para el entrenamiento multimodal a gran escala.
Supone una importante mejora de la fidelidad, la coherencia y el movimiento con respecto a Gen-2, y un paso más hacia la creación de modelos del mundo generales.
Gen-3 Alpha se diseñó desde cero para aplicaciones creativas, lo que le permite comprender y generar una amplia gama de estilos e instrucciones artísticas.
JEN, nuevo modelo para generación de música a partir de texto
Jen es una innovadora plataforma en el mundo de la música, combinando tecnología blockchain y AI para transformar la forma en que se crean y distribuyen las canciones, estableciendo un nuevo estándar en cumplimiento de derechos de autor.
El modelo utiliza la red blockchain de The Root Network para generar un hash criptográfico único para cada pista musical. Este proceso asegura la integridad y el registro temporal de la creación de cada track, otorgando a los outputs verificados un distintivo JENUINE™.
Jen fue cofundada por Shara Senderoff, reconocida en Rolling Stone’s “Future 25" y Billboard’s “Women in Music”, y Mike Caren, un veterano de la industria musical. Junto a ellos están Aaron McDonald, cofundador de Futureverse, y el Dr. Alex Wang, un PhD en AI que ha liderado el desarrollo tecnológico de Jen.
En Jen, los usuarios son propietarios de las pistas que crean. Con el próximo lanzamiento de R3CORD™, los usuarios podrán “grabar” sus pistas para hacerlas vendibles, añadiendo una capa de mercado a las creaciones personales.
Este modelo ofrece herramientas avanzadas para potenciar la creatividad de los músicos. Estas son sus funciones más destacadas:
Continuation: Extiende una pista a la longitud deseada o explora una vía sonora alternativa. Perfecto para aquellos momentos en los que una melodía necesita un poco más de desarrollo o un toque diferente.
Inpainting: Rellena partes faltantes de una pista con nueva música que encaja perfectamente dentro de la composición existente. Ideal para aquellos que necesitan completar sus creaciones sin perder la coherencia musical.
Composer: Una herramienta versátil de generación multi-pista, con capacidad de iteración infinita, que produce stems a partir de un solo prompt o para complementar ideas subidas por el usuario.
StyleFilter™️: Permite subir un instrumento, género o pista única para crear un StyleFilter que estiliza fácilmente una nueva obra maestra con el sonido deseado.
Today, we couldn't be more excited to premiere Jen [ALPHA]. 🎵
Our ethically-trained generative AI music platform introduces a new standard for copyright compliance in text-to-music generation. Now, you can make music with your mind on jenmusic.ai.
— Jen (@jenmusicai)
4:07 PM • Jun 20, 2024
NVIDIA lanzA su propio modelo de código abierto Nemotron-4 340B
Se trata de una familia de modelos abiertos para generar datos sintéticos con los que entrenar LLM para aplicaciones comerciales.
Esta familia de modelos incluye: Nemotron-4-340B-Base, Nemotron-4-340B-Instruct y Nemotron-4-340B-Reward.
The Prompt Report: Un Exhaustivo Estudio de Técnicas de Prompting y GenAI
The Prompt Report, un informe de 76 páginas, analiza más de 1,500 artículos sobre técnicas de prompting, agentes y GenAI, liderado por @learnprompting junto a expertos de OpenAI, Microsoft y la Universidad de Maryland.
Puntos clave:
Categorías de Técnicas de Prompts: El informe desglosa 200 técnicas de prompts en siete categorías: Text-based Prompting, Multilingual Techniques, Multimodal Techniques, Agents, Evaluation, Security y Alignment.
Benchmarking y Resultados: Se evaluaron las técnicas en MMLU y un nuevo benchmark, documentando los 40+ pasos que siguió un ingeniero de prompts experto para lograr los mejores resultados. Entre las principales técnicas destacadas, DSPy superó a un ingeniero de prompts humano en un 50%, ahorrando más de 20 horas.
Importancia e Implicaciones: The Prompt Report es la revisión más completa sobre técnicas de prompting disponible, estructurando el campo y fomentando nuevas investigaciones.
Google presenta su tecnología V2A, que utiliza píxeles de vídeo e indicaciones de texto para generar bandas sonoras enriquecidas
La generación de videos está avanzando rápidamente, pero la mayoría de los modelos actuales no generan sonido. Este nuevo avance en tecnología Video-to-Audio (V2A) promete cambiar eso, combinando píxeles de video y prompts de texto para crear bandas sonoras sincronizadas.
Puntos Clave:
Generación Sincrónica de Audio y Video: La tecnología V2A permite generar bandas sonoras detalladas y sincronizadas con la acción en pantalla usando prompts de texto. Esto abre la puerta a películas generadas con efectos sonoros realistas, música dramática y diálogos que coinciden con los personajes y el tono del video.
Flexibilidad y Control Creativo: V2A puede generar un número ilimitado de bandas sonoras para cualquier video, permitiendo experimentación rápida y selección del mejor audio. Los usuarios pueden usar prompts positivos para guiar hacia sonidos deseados o negativos para evitar sonidos indeseados, proporcionando un control creativo sin precedentes.
Enfoque Innovador y Desafíos: Utilizando un enfoque basado en difusión, V2A genera audio a partir de ruido aleatorio, refinándolo iterativamente hasta crear una pista de sonido realista. A pesar de su innovación, enfrenta desafíos como la sincronización de labios y la dependencia de la calidad del video de entrada.
V2A representa un paso significativo hacia una experiencia cinematográfica generada completamente por inteligencia artificial.
Robots
Punyo, robot con IA de Toyota demuestra más de 100 habilidades con una tecnología impactante
El robot Punyo es un robot humanoide de Toyota diseñado para ayudar a los usuarios en las tareas cotidianas del día a día. Punyo puede agarrar y sostener objetos con todo su cuerpo, lo que aumenta ampliamente su potencial de uso.